

Microsoft Fabric: Mit Eventstreams Echtzeitdaten verarbeiten
Nachdem wir uns im letzten Artikel einen Überblick über Real-Time Intelligence in Microsoft Fabric verschafft haben, gehen wir heute eine Ebene tiefer und betrachten Eventstreams etwas genauer.
Events & Streams allgemein
Vergegenwärtigen wir uns als Einstieg einmal ganz unabhängig von Fabric, was ein „Event“ bzw. „Eventstream“ ist.
Stellen wir uns zum Beispiel vor, dass wir in einem Lagerhaus verderbliche Lebensmittel lagern. Wir wollen sichergehen, dass es immer kühl genug ist, und deshalb die Temperatur überwachen. Dazu haben wir einen Sensor installiert, der einmal pro Sekunde die aktuelle Temperatur übermittelt.
Wann immer das geschieht, nennen wir das ein Event. Über die Zeit hinweg betrachtet haben wir dann eine Folge von Events, die (theoretisch) niemals endet – also einen Stream von Events.
Auf abstrakter Ebene ist ein Event ein Datenpaket, das zu einem bestimmten Zeitpunkt emittiert wird und typischerweise eine Zustandsänderung beschreibt – etwa bei Temperaturen, Aktienkursen oder Fahrzeug-Standorten.
Eventstreams in Fabric
Kommen wir zu Microsoft Fabric. Hier repräsentiert ein Eventstream einen Strom von Events, der von (mindestens) einer Quelle ausgeht, optional transformiert wird und an (mindestens) ein Ziel geleitet wird.
Schön dabei ist, dass das Ganze komplett ohne Coding funktioniert. Eventstreams können ganz einfach über die Benutzeroberfläche im Browser erstellt und konfiguriert werden.
Hier ein Beispiel, wie ein Eventstream aussehen kann:

Jeder Eventstream setzt sich aus 3 verschiedenen Arten von Bausteinen zusammen, die wir uns im Folgenden genauer anschauen:
- ① Quellen
- ② Transformationen
- ③ Ziele
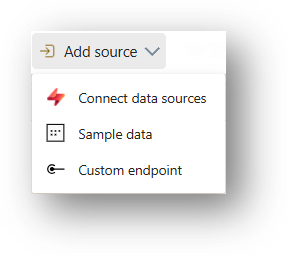
① Quellen
Für den Anfang braucht man eine Datenquelle, die Events liefert.
Technologisch gibt es hier eine große Auswahl an unterstützten Möglichkeiten. Neben Microsoft-Technologien (z.B. Azure IoT Hub, Azure Event Hub, OneLake events) umfasst diese u.a. auch Apache Kafka-Streams, Amazon Kinesis Data Streams, Google Cloud Pub/Sub und Change Data Captures.
Wenn das alles nicht reicht, kann man einen Custom Endpoint nutzen. Dieser unterstützt die Protokolle Kafka, AMQP und außerdem Event Hub. Eine Übersicht aller unterstützten Quellen gibt es hier.
Tipp: Von Microsoft gibt es verschiedene „Sample“-Datenquellen, die zum Ausprobieren und Experimentieren sehr praktisch sind.
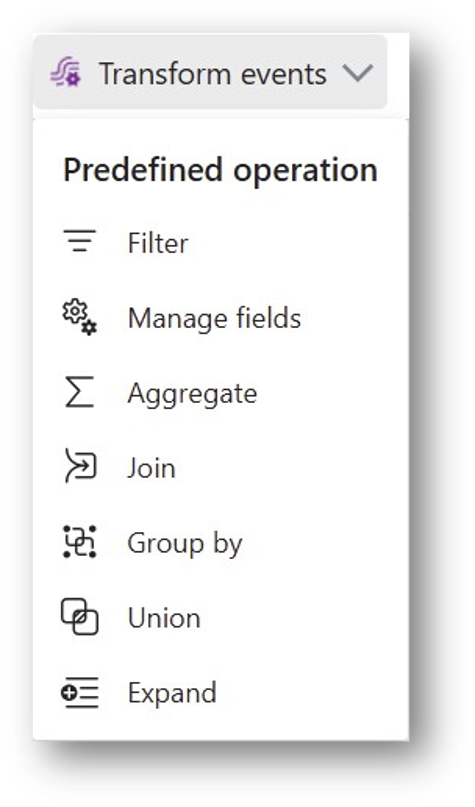
② Transformationen
Die Eventdaten können nun auf verschiedene Weise bereinigt und transformiert werden. Dazu fügt man nach der Quelle einen der Transformationsoperatoren hinzu und konfiguriert diesen. Man kann so u.a. die eingehenden Daten filtern, kombinieren und aggregieren, Felder auswählen usw.
Beispiel: Nehmen wir an, die Datenquelle liefert uns mehrmals pro Sekunde die aktuelle Raumtemperatur, aber für unsere geplante Analyse wäre eine Granularität von einer Minute schon vollkommen ausreichend. Wir nutzen deshalb „Group by“ um pro Zeitfenster von 5 Sekunden die durchschnittliche, minimale und maximale Temperatur zu berechnen. Damit reduzieren wir das Datenvolumen (und damit verbundene Kosten) vor dem Abspeichern beträchtlich und erhalten trotzdem alle relevanten Informationen.
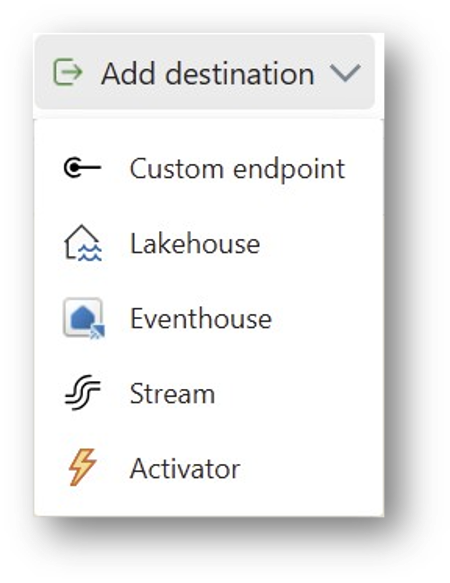
③ Ziele (Destinations)
Nach Durchlaufen aller Transformationsschritte werden die Eventdaten an ein Ziel geleitet. Meistens ist das Ziel eine Tabelle in einem Eventhouse. Ingesamt unterstützt werden:
- Eventhouses: Ein Eventhouse ist ein für Events optimierter Datenspeicher in Fabric, der kontinuierliches Einspeisen neuer Daten und sehr schnelle Analysen darauf unterstützt. Auf Eventhouses werden wir im Detail in einem weiteren Blog-Post eingehen.
- Lakehouse: Ein Lakehouse ist der „typische“ Datenspeicher in Fabric in klassischen (Batch-)Szenarien. Es unterstützt sowohl strukturierte als auch unstrukturierte Daten.
- Activator: Ein Activator ermöglicht es, unter bestimmten Bedingungen Aktionen auszulösen. Zum Beispiel könnte automatisch eine E-Mail verschickt werden, wenn die gemessene Temperatur einen Schwellwert überschreitet. Für komplexere Fälle kann man einen Power Automate Flow auslösen.
- Stream: Ein weiterer Eventstream („abgeleiteter Stream“). Man hat also die Möglichkeit, Eventstreams zu verketten. Das kann hilfreich sein, um komplexe Logik aufzubrechen und Wiederverwendung zu ermöglichen.
- Custom Endpoint: Analog zu den Quellen kann man auch als Ziel einen Custom Endpoint nutzen und so beliebige Drittsysteme anbinden. Unterstützt werden auch hier Kafka, AMQP und Event hub.
Eventstreams unterstützen auch mehrere Ziele. Das kann hilfreich sein, wenn man zum Beispiel eine Lambda-Architektur umsetzen möchte: Man speichert feingranulare Daten (z.B. auf Sekundenbasis) für begrenzte Zeit in einem Eventhouse, um Echtzeitszenarien zu unterstützen. Parallel dazu aggregiert man die Daten (z.B. auf Minutenbasis) und speichert das Ergebnis für historische Datenanalysen in einem Lakehouse.
Kosten
Um Eventstreams nutzen zu können, braucht man eine kostenpflichtige Fabric Capacity. Microsoft empfiehlt dabei mindestens eine F4 SKU (die monatlichen Preise dafür findet man hier). Welche Ausbaustufe tatsächlich ausreichend ist, hängt von mehreren Faktoren ab – insbesondere der benötigten Rechenleistung, dem Datenvolumen und der Eventstream-Laufzeit. Details kann man hier nachlesen.
Sollte man einen Eventstream vorübergehend nicht benötigen, kann man ihn deaktivieren und so vermeiden, seine Fabric Capacity unnötig zu belasten. Genau genommen geht dies sogar separat für alle Quellen und Ziele.
Autor

Rupert Schneider
Fabric Data Engineer bei scieneers GmbH
rupert.schneider@scieneers.de





