Zwei Tage lang haben sich die meisten Kolleginnen und Kollegen aus Karlsruhe, Köln und Hamburg in Hamburg getroffen, um sich über fachliche und interne Themen auszutauschen, neue Impulse zu erhalten und gemeinsame Erlebnisse zu teilen.
Nachdem wir uns im letzten Artikel einen Überblick über Real-Time Intelligence in Microsoft Fabric verschafft haben, gehen wir heute eine Ebene tiefer und betrachten Eventstreams etwas genauer.
Events & Streams allgemein
Vergegenwärtigen wir uns als Einstieg einmal ganz unabhängig von Fabric, was ein „Event“ bzw. „Eventstream“ ist.
Stellen wir uns zum Beispiel vor, dass wir in einem Lagerhaus verderbliche Lebensmittel lagern. Wir wollen sichergehen, dass es immer kühl genug ist, und deshalb die Temperatur überwachen. Dazu haben wir einen Sensor installiert, der einmal pro Sekunde die aktuelle Temperatur übermittelt.
Wann immer das geschieht, nennen wir das ein Event. Über die Zeit hinweg betrachtet haben wir dann eine Folge von Events, die (theoretisch) niemals endet – also einen Stream von Events.
Auf abstrakter Ebene ist ein Event ein Datenpaket, das zu einem bestimmten Zeitpunkt emittiert wird und typischerweise eine Zustandsänderung beschreibt – etwa bei Temperaturen, Aktienkursen oder Fahrzeug-Standorten.
Eventstreams in Fabric
Kommen wir zu Microsoft Fabric. Hier repräsentiert ein Eventstream einen Strom von Events, der von (mindestens) einer Quelle ausgeht, optional transformiert wird und an (mindestens) ein Ziel geleitet wird.
Schön dabei ist, dass das Ganze komplett ohne Coding funktioniert. Eventstreams können ganz einfach über die Benutzeroberfläche im Browser erstellt und konfiguriert werden.
Hier ein Beispiel, wie ein Eventstream aussehen kann:
Jeder Eventstream setzt sich aus 3 verschiedenen Arten von Bausteinen zusammen, die wir uns im Folgenden genauer anschauen:
① Quellen
② Transformationen
③ Ziele
① Quellen
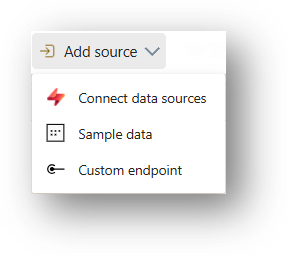
Für den Anfang braucht man eine Datenquelle, die Events liefert.
Technologisch gibt es hier eine große Auswahl an unterstützten Möglichkeiten. Neben Microsoft-Technologien (z.B. Azure IoT Hub, Azure Event Hub, OneLake events) umfasst diese u.a. auch Apache Kafka-Streams, Amazon Kinesis Data Streams, Google Cloud Pub/Sub und Change Data Captures.
Wenn das alles nicht reicht, kann man einen Custom Endpoint nutzen. Dieser unterstützt die Protokolle Kafka, AMQP und außerdem Event Hub. Eine Übersicht aller unterstützten Quellen gibt es hier.
Tipp: Von Microsoft gibt es verschiedene „Sample“-Datenquellen, die zum Ausprobieren und Experimentieren sehr praktisch sind.
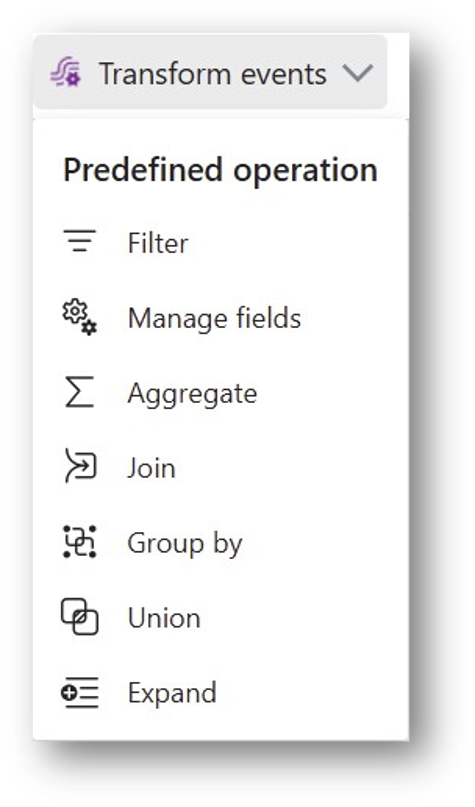
② Transformationen
Die Eventdaten können nun auf verschiedene Weise bereinigt und transformiert werden. Dazu fügt man nach der Quelle einen der Transformationsoperatoren hinzu und konfiguriert diesen. Man kann so u.a. die eingehenden Daten filtern, kombinieren und aggregieren, Felder auswählen usw.
Beispiel: Nehmen wir an, die Datenquelle liefert uns mehrmals pro Sekunde die aktuelle Raumtemperatur, aber für unsere geplante Analyse wäre eine Granularität von einer Minute schon vollkommen ausreichend. Wir nutzen deshalb „Group by“ um pro Zeitfenster von 5 Sekunden die durchschnittliche, minimale und maximale Temperatur zu berechnen. Damit reduzieren wir das Datenvolumen (und damit verbundene Kosten) vor dem Abspeichern beträchtlich und erhalten trotzdem alle relevanten Informationen.
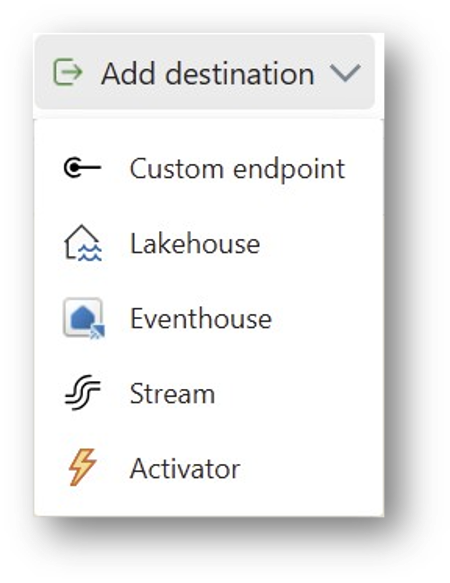
③ Ziele (Destinations)
Nach Durchlaufen aller Transformationsschritte werden die Eventdaten an ein Ziel geleitet. Meistens ist das Ziel eine Tabelle in einem Eventhouse. Ingesamt unterstützt werden:
Eventhouses: Ein Eventhouse ist ein für Events optimierter Datenspeicher in Fabric, der kontinuierliches Einspeisen neuer Daten und sehr schnelle Analysen darauf unterstützt. Auf Eventhouses werden wir im Detail in einem weiteren Blog-Post eingehen.
Lakehouse: Ein Lakehouse ist der „typische“ Datenspeicher in Fabric in klassischen (Batch-)Szenarien. Es unterstützt sowohl strukturierte als auch unstrukturierte Daten.
Activator: Ein Activator ermöglicht es, unter bestimmten Bedingungen Aktionen auszulösen. Zum Beispiel könnte automatisch eine E-Mail verschickt werden, wenn die gemessene Temperatur einen Schwellwert überschreitet. Für komplexere Fälle kann man einen Power Automate Flow auslösen.
Stream: Ein weiterer Eventstream („abgeleiteter Stream“). Man hat also die Möglichkeit, Eventstreams zu verketten. Das kann hilfreich sein, um komplexe Logik aufzubrechen und Wiederverwendung zu ermöglichen.
Custom Endpoint: Analog zu den Quellen kann man auch als Ziel einen Custom Endpoint nutzen und so beliebige Drittsysteme anbinden. Unterstützt werden auch hier Kafka, AMQP und Event hub.
Eventstreams unterstützen auch mehrere Ziele. Das kann hilfreich sein, wenn man zum Beispiel eine Lambda-Architektur umsetzen möchte: Man speichert feingranulare Daten (z.B. auf Sekundenbasis) für begrenzte Zeit in einem Eventhouse, um Echtzeitszenarien zu unterstützen. Parallel dazu aggregiert man die Daten (z.B. auf Minutenbasis) und speichert das Ergebnis für historische Datenanalysen in einem Lakehouse.
Kosten
Um Eventstreams nutzen zu können, braucht man eine kostenpflichtige Fabric Capacity. Microsoft empfiehlt dabei mindestens eine F4 SKU (die monatlichen Preise dafür findet man hier). Welche Ausbaustufe tatsächlich ausreichend ist, hängt von mehreren Faktoren ab – insbesondere der benötigten Rechenleistung, dem Datenvolumen und der Eventstream-Laufzeit. Details kann man hier nachlesen.
Sollte man einen Eventstream vorübergehend nicht benötigen, kann man ihn deaktivieren und so vermeiden, seine Fabric Capacity unnötig zu belasten. Genau genommen geht dies sogar separat für alle Quellen und Ziele.
In der heutigen Geschäftswelt versucht man mehr und mehr, Entscheidungen und Prozesse auf ein solides Fundament von Daten zu stellen. Die technische Antwort darauf sind typischerweise Data Warehouses und Dashboards, die Unternehmensdaten bündeln und durch Visualisierung für jeden verständlich und nutzbar machen.
In der Umsetzung verlässt man sich häufig auf Batch-Processing, bei dem die Daten in einem automatischen Prozess gesammelt und aufbereitet werden – beispielsweise einmal pro Tag, seltener schon stündlich oder im Abstand von einigen Minuten.
Dieser Ansatz funktioniert für viele Anwendungsfälle gut. Er stößt aber dann an seine Grenzen, wenn wir Informationen „in Echtzeit“ analysieren möchten und höchstens eine Verzögerung von wenigen Sekunden in Kauf nehmen können. Einige Beispiele:
Produktion: Überwachung von Sensordaten, um Maschinenausfälle zu vermeiden („Predictive Maintenance“)
Supply Chain: Tracking von Standortdaten und Wetterereignissen, um Lieferverzögerungen frühzeitig zu erkennen
Finanzwesen: Sekundengenaue Überwachung und Analyse von Aktienkursen
IT: Auswertung von Log-Daten, um nach Updates Probleme sofort zu erkennen
Marketing: Analyse von Social Media Posts während einem Live-Event
Neu ist das alles nicht, aber bisherige Lösungen waren in der Umsetzung oft aufwendig und erforderten viel Fachwissen.
Genau hier hat Microsoft angesetzt: 2024 wurde die Fabric-Plattform mit Real-Time Intelligence um verschiedene Bausteine erweitert, mit denen man einen Großteil der Komplexität umgeht und schnell zu funktionierenden Lösungen kommt.
In kommenden Artikeln erklären wir die wichtigsten dieser Bausteine „Fabric Items“ genauer. Hier ein kurzer Überblick:
Eventstream
Eventstreams empfangen kontinuierlich Echtzeitdaten (Events) aus verschiedensten Quellen. Diese werden bei Bedarf transformiert und letztlich an ein Ziel weitergeleitet, das für die Speicherung der Daten zuständig ist. Typischerweise ist das Ziel ein Eventhouse. Code wird nicht benötigt.
Eventhouse
Ein Eventhouse ist ein optimierter Datenspeicher für Events. Es enthält mindestens eine KQL-Datenbank, in der die Event-Daten in Tabellenform gespeichert werden.
Real-Time Dashboard
Real-Time Dashboards haben Ähnlichkeit zu Power-BI-Reports, sind aber eine von Power BI unabhängige, eigenständige Lösung. Ein Real-Time Dashboard enthält Kacheln mit Visuals (z.B. Diagramme oder Tabellen). Diese sind interaktiv und man kann etwa Filter setzen. Jedes Visual holt sich die notwendigen Daten über eine Datenbankabfrage, die man in KQL (Kusto Query Language) formuliert – typischerweise aus einem Eventhouse.
Activator
Activator ermöglicht es, unter bestimmten Bedingungen automatisch eine Aktion auszuführen, beispielsweise basierend auf einem Real-Time Dashboard oder einer KQL Query. Die Aktion ist im einfachsten Fall das Senden einer Nachricht per E-Mail oder Teams; man kann aber auch einen Power Automate Flow anstoßen.
Was muss ich also lernen, um mit Real-Time Intelligence eine Lösung umzusetzen?
Es läuft im Wesentlichen auf KQL und ein Grundverständnis der erwähnten Fabric Items hinaus. Vieles ist No-Code. KQL ist zwar im Vergleich zu SQL weniger verbreitet, die Grundlagen sind aber leicht zu lernen und es fühlt sich schon nach kurzer Zeit natürlich an.
In unserem Blogmelden wir uns bald mit weiteren Posts zum Thema Fabric Real-Time Intelligence und steigen tiefer in die verschiedenen Themenbereiche ein.
https://www.scieneers.de/wp-content/uploads/2025/05/real_time_intelligence_1030x258.jpg258344Rupert Schneiderhttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngRupert Schneider2025-05-23 09:37:392025-05-23 14:46:06Real-Time Intelligence: Echtzeitdaten in Microsoft Fabric
Auf der diesjährigen Minds Mastering Machines (M3) Konferenz in Karlsruhe standen neben Best Practices zu GenAI, RAG-Systemen auch Praxisberichte aus verschiedenen Branchen, Agentensysteme und LLM sowie rechtliche Aspekte von ML im Fokus. Wir haben drei Vorträge zu unseren Projekten gehalten.
Globale Modelle wie TFT und TimesFM revolutionieren die Fernwärmeprognose, indem sie präzisere Vorhersagen ermöglichen, Synergien zwischen Systemen nutzen und das Cold-Start-Problem effektiv lösen.
Die CI/CD-Pipeline dauert ewig? Das lokale Bauen eines Container-Images dauert viel zu lange? Ein möglicher Grund dafür könnte die Größe der Container-Images sein – oft sind sie unnötig aufgebläht. In diesem Artikel werden verschiedene Strategien vorgestellt, um Images zu optimieren und effizienter und schneller zu gestalten. 🚀
Keine unnötigen Dependencies
Ein gewachsenes Projekt mit zahlreichen Abhängigkeiten in der pyproject.toml kann schnell unübersichtlich werden. Bevor der nächste Schritt – beispielsweise die Containerisierung mit Docker – angegangen wird, lohnt es sich zunächst zu prüfen, welche Abhängigkeiten tatsächlich noch benötigt werden und welche mittlerweile obsolet sind. So lässt sich die Codebasis verschlanken, potenzielle Sicherheitsrisiken reduzieren und die Wartbarkeit verbessern.
Eine Möglichkeit wäre, alle Dependencies sowie das Virtual Environment zu löschen und anschließend den Quellcode Datei für Datei durchzugehen, um nur noch die wirklich benötigten Abhängigkeiten hinzuzufügen. Eine effizientere Strategie bietet das Command-Line-Tool deptry. Es übernimmt diese mühsame Aufgabe und hilft dabei, überflüssige Abhängigkeiten schnell zu identifizieren. Die Installation erfolgt mit
uv add --dev deptry
Anschließend lässt sich die Analyse des Projekts direkt im Projektordner mit folgendem Befehl starten
deptry .
Danach listet deptry die Dependencies auf die nicht mehr benutzt werden
Scanning 126 files...
pyproject.toml: DEP002 'pandas' defined as a dependency but not used in the codebase
Found 1 dependency issue.
In diesem Fall scheint pandas nicht mehr genutzt zu werden. Es empfiehlt sich, dies zu überprüfen und anschließend alle nicht mehr benötigten Abhängigkeiten zu entfernen.
uv remove pandas
Alternativer Index
Wenn ein Paket wie pytorch, docling oder sparrow genutzt wird, das torch(vision) als Abhängigkeit enthält, und ausschließlich die CPU zum Einsatz kommen soll, kann auf die Installation der CUDA-Bibliotheken verzichtet werden. Dies lässt sich erreichen, indem für torch(vision) ein alternativer Index angegeben wird. uv sucht das Paket dann zunächst dort, wobei in diesem Index keine Abhängigkeiten zu den CUDA-Bibliotheken für torch(vision) definiert sind. Dazu wird in der pyproject.toml unter dependencies folgender Eintrag ergänzt:
[tool.uv.sources]
torch = [
{ index = "pytorch-cpu" },
]
torchvision = [
{ index = "pytorch-cpu" },
]
[[tool.uv.index]]
name = "pytorch-cpu"
url = "https://download.pytorch.org/whl/cpu"
So sehen die Images mit und ohne alternativem Index aus:
REPOSITORY TAG IMAGE ID CREATED SIZE
sample_torchvision gpu f0f89156f089 5 minutes ago 6.46GB
sample_torchvision cpu 0e4b696bdcb2 About a minute ago 657MB
Mit dem alternativen Index ist das Image nur noch 1/10 so groß!
Das richtige Dockerfile
Unabhängig davon, ob das Python-Projekt gerade erst startet oder bereits länger besteht, lohnt sich ein Blick auf die von uv bereitgestellten Beispiel-Dockerfiles: uv-docker-example.
Diese bieten eine sinnvolle Grundkonfiguration und sind darauf optimiert, möglichst kleine Images zu erzeugen. Sie sind ausführlich kommentiert und nutzen ein minimales Base-Image mit vorinstalliertem Python und uv. Dependencies und das Projekt werden in separaten Befehlen installiert, sodass das Layer-Caching optimal funktioniert. Dabei werden nur die regulären Dependencies installiert, während Dev-Dependencies wie das oben installierte deptry ausgelassen werden.
Im Multi-Stage-Sample werden zudem nur das Virtual Environment und die Projektdateien in das Runtime-Image kopiert, sodass keine überflüssigen Build-Artefakte im finalen Image landen.
Bonustipp für Azure WebApp Nutzer
Dieser Tipp verkleinert zwar nicht das Image, kann einem aber im Ernstfall einige Kopfschmerzen ersparen.
Wenn das Docker-Image in einer Azure WebApp deployed wird, sollte /home oder darunterliegende Pfade nicht als WORKDIR verwenden. Der /home-Pfad kann genutzt werden, um Daten über mehrere WebApp-Instanzen hinweg zu teilen. Dies wird durch die Umgebungsvariable WEBSITES_ENABLE_APP_SERVICE_STORAGE gesteuert. Ist diese auf true gesetzt, wird der gemeinsame Speicher nach /home gemountet, wodurch die im Image enthaltenen Dateien im Container nicht mehr sichtbar sind.
(Wenn das Dockerfile sich an den uv-Beispielen orientiert, dann ist das WORKDIR bereits korrekt unter „/app“ konfiguriert.)
https://www.scieneers.de/wp-content/uploads/2025/03/ChatGPT-Image-Apr-1-2025-09_43_18-PM.png10241536Sebastian Drewkehttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngSebastian Drewke2025-04-02 21:11:072025-04-11 09:45:13Kleinere Docker Images mit uv
Lernen Sie Microsoft Fabric in unseren Webinaren kennen
Einführung
Unsere Termine
In unserem kostenfreien Webinar geben wir Sie eine Einführung in Microsoft Fabric und zeigen live, wie Sie mit Lakehouse, Dataflows und Power BI Dashboards arbeiten.
In unserem kostenfreien Webinar erhalten Sie einen fundierten Einblick mit spannenden Live-Demos in die Erstellung von Echtzeit-Dashboards mit der Kusto Query Language (KQL).
Fast jedes Unternehmen betreibt Forschung und Entwicklung (R&D), um innovative Produkte auf den Markt zu bringen. Die Entwicklung innovativer Produkte ist naturgemäß risikobehaftet: da es um Produkte geht, die noch nie zuvor angeboten wurden, ist meistens unklar, ob und zu welchem Grad erwünschte Eigenschaften der Produkte realisierbar sind und wie genau sie sich realisieren lassen. Der Erfolg von R&D hängt also maßgeblich an der Gewinnung und Verwertung von Wissen über die Realisierbarkeit von Produkteigenschaften.
Scrum ist heute mit Abstand die beliebteste Form des agilen Projektmanagements1. Einige Hauptmerkmale von Scrum sind stetige Transparenz über den Produktfortschritt, Zielorientierung, einfache Abläufe, flexible Arbeitsweisen und effiziente Kommunikation. Scrum ist ein flexibles Rahmenwerk und beinhaltet nur eine Handvoll Aktivitäten und Artefakte2. Scrum lässt absichtlich offen, wie Backlog Items (BLIs) strukturiert sind, was die Definition of Done (DoD) von BLIs ist und wie genau derRefinement-Prozess ablaufen sollte. Diese Aspekte muss ein Scrum Team selbst steuern. Auch durch diese Flexibilität ist Scrum so erfolgreich: Scrum wird in einer Vielzahl von Domänen angewendet und dort mit domänenspezifischen Prozessen oder Artefakten ergänzt3.
Auch in R&D ist Scrum fest etabliert4. Wie oben beschrieben hängt der Erfolg eines R&D Scrum Teams davon ab, wie effizient das Team Wissen gewinnt und verwertet. Zur Wissensgewinnung haben sich im Scrum Kontext sogenannte Spikes etabliert. Spikes sind BLIs, in denen Wissen über die Machbarkeit und den Aufwand von Produkteigenschaften gewonnen wird, ohne die Eigenschaften zu realisieren. In diesem Post wollen wir aufzeigen, worauf es bei der Umsetzung von Spikes in Scrum ankommt und wie ein Scrum Team sicherstellen kann, dass das aus Spikes gewonnene Wissen optimal verwertet wird. Wir illustrieren diese Good Practices mit konkreten Beispielen aus 1,5 Jahren Scrum in einem Forschungsprojekt mit EnBW.
Eine breit etablierte Methode zur Wissensgewinnung in Scrum sind sogenannte Spikes– BLIs, in denen die Machbarkeit und der Aufwand von Produkteigenschaften eingeschätzt werden, ohne die Eigenschaften zu realisieren. Die Idee von Spikes entstammt dem eXtreme Programming (XP)5.
Die Wissensgewinnung durch Spikes dient dem Abbau von übermäßigem Risiko6. Der Anteil von Spikes am Backlog sollte also proportional zum aktuellen Risiko bei der Produktentwicklung sein. In einem R&D Scrum Team kann es viele offene Fragen und Risiken geben und Spikes können mehr als die Hälfte eines Sprints ausmachen, wie z.B. zeitweise im Google AdWords Scrum Team7. Ein übergroßer Anteil von Spikes hemmt allerdings die Produktivität eines Teams, weil zu viel Zeit mit Wissensgewinnung und zu wenig Zeit mit der Umsetzung des Produkts verbracht wird8. Die Priorisierung von Spikes gegenüber regulären BLIs ist also ein wichtiger Faktor für den Erfolg von R&D Scrum Projekten.
Ein weiterer wichtiger Faktor ist die Definition von Qualitätskriterien für Spikes. Konkret kann ein Scrum Team eine Definition of Ready (DoR) und eine Definition of Done (DoD) für Spikes etablieren. Die DoR legt fest, welche Kriterien ein Spike erfüllen muss, um bearbeitet zu werden; die DoD bestimmt welche Kriterien erfüllt sein müssen damit ein Spike abgeschlossen werden kann. Beide Definitionen beeinflussen die Qualität und Menge des erzeugten Wissens und dessen Verwertbarkeit im Scrum Prozess. Die DoD ist ein obligatorischer Bestandteil von Scrum. Die Einführung einer DoR liegt hingegen im Gestaltungsspielraum des Scrum Teams und ist auch nicht immer nützlich9.
Anlass für einen Spike ist fast immer ein akutes und konkretes Risiko bei der Produktentwicklung. Erkenntnisse aus einem Spike können aber über den konkreten Anlass des Spikes hinaus wertvoll sein und langfristig bei Entscheidungen in der Produktentwicklung helfen. Um eine Langzeitwirkung zu entfalten, müssen Erkenntnisse aus Spikes vom Team geeignet aufbewahrt werden.
Die Anwendung von Spikes in R&D Projekten wirft also mindestens drei Fragen auf:
Wie werden Spikes untereinander und gegenüber anderen BLIs priorisiert?
Wie werden DoR und DoD für Spikes formuliert?
Wie wird das in Spikes gewonnene Wissen aufbewahrt?
Die Literatur über Scrum lässt diese Fragen weitgehend offen. In einem mehrjährigen R&D Forschungsprojekt mit EnBW konnten wir verschiedenen Antworten auf die Fragen anwenden und damit Erfahrungen sammeln. Dabei haben wir zwei Good Practices entwickelt, die wir in diesem Blogpost vorstellen: (1) ein Regeltermin zur „Spike-Pflege“, d.h. zum Schärfen konkreter Hypothesen in Spikes und (2) ein leichtgewichtiges Laborbuchzur Protokollierung von Erkenntnissen. Die beiden Praktiken ergänzen wir außerdem durch eine passende DoR und DoD.
Good Practice: Regeltermin für die „Spike-Pflege“ im Backlog
Das Refinement ist eine fortlaufende Aktivität des gesamten Scrum Teams. Dabei werden BLIs aus dem Backlog für die Bearbeitung vorbereitet: BLIs werden präziser reformuliert, in unabhängige BLIs aufgeteilt und in konkrete Arbeitsschritte zerlegt. Viele Scrum Teams nutzen einen Regeltermin, um das Refinement gemeinsam durchzuführen und dabei ein gemeinsames Verständnis des Backlogs zu erlangen.
Unserer Erfahrung nach ist ein gemeinsames Refinement ein häufiger Entstehungsort für Spikes. Denn wenn das Team über das Backlog diskutiert, fallen ungeklärte Fragen und Risiken auf. Offene Risiken in einem BLI äußern sich oft darin, dass das Team Schwierigkeiten hat eine konkrete DoD festzulegen und dass die Aufwandsschätzungen der Teammitglieder stark auseinandergehen. Auch bestimmte Formulierungen von Teammitglieder können auf Risiken hinweisen, z.B.:
„Keine Ahnung, ob das geht.“
„Ich weiß noch nicht, wie ich das machen soll.“
„Da muss ich mich erstmal einlesen.“
Nach der Identifizierung eines Risikos muss das Team entscheiden, ob das Risiko so groß ist, dass es mit einem Spike reduziert werden sollte. Der Spike wird dann im Backlog als BLI-Entwurf angelegt. Um den regulären Refinement-Termin nicht zu sprengen, empfehlen wir, frisch angelegte Spikes nicht in diesem Termin zu refinen und zu priorisieren. Stattdessen empfehlen wir, dass sich das Team regelmäßig ein bis zwei Tage nach dem regulären Refinement trifft, um „Spike-Pflege“ zu betreiben. In der Zwischenzeit können die Spike-Entwürfe auch einzelnen Teammitgliedern zugeteilt werden, die diese dann für den Spike-Pflege-Termin vorbereiten, z.B. durch Sammlung konkreter Hypothesen und Ideen für Experimente.
Natürlich können Spikes auch außerhalb eines gemeinsamen Refinement Termins entstehen, z.B. während der Umsetzung eines BLIs. Auch dann bietet es sich an, die Spikes als Entwürfe zu sammeln und dann im nächsten Spike-Pflege-Termin nachzuschärfen. So geraten die Anlässe der Spikes nicht in Vergessenheit, führen aber auch nicht zu Scope Creep im aktuellen Sprint.
Im Spike-Pflege-Termin müssen die gesammelten Spikes schließlich refined und im Backlog priorisiert werden. Unserer Erfahrung nach haben die meisten Spikes einen direkten Bezug zu einem oder mehreren BLIs – nämlich die BLIs bei deren Umsetzung es akut Risiken gibt. In diesem Fall ist die Priorisierung einfach: man nutzt die bestehende Priorisierung der BLIs und fügt jeden Spike vor seinem zugehörigen BLI in die Liste ein.
Zur Aufbewahrung des gewonnenen Wissens aus Spikes schlagen wir einleichtgewichtiges Laborbuch vor. Das Laborbuch dokumentiert für jeden Spike folgende Aspekte in jeweils 1-2 Sätzen:
Problemstellung: Welches akute Risiko in der Produktentwicklung soll entschärft werden? Welche Fragen müssen dafür geklärt werden?
Hypothesen: Aufstellung möglichst konkreter Hypothesen, die sich entweder recherchieren oder experimentell prüfen lassen.
Erkenntnisse: Zusammenfassung der experimentellen Ergebnisse oder der Recherche.
Konsequenzen: Bedeutung der Erkenntnisse für das Produkt. Z.B. „Produkteigenschaft X kann mithilfe von Y erreicht werden, mit Z aber nicht.“
Relevante Links, z.B. zu detaillierten experimentellen Ergebnissen und BLIs
Entscheidend für den langfristigen Mehrwert des Laborbuchs sind dessen Vollständigkeit und Kompression. Vollständigkeit heißt, dass die Ergebnisse sämtlicher Spikes im Laborbuch landen; Kompression heißt, dass nur die wesentlichen Erkenntnisse und Konsequenzen für das Projekt kurz und knapp in das Laborbuch eingetragen werden. In dieser Qualität kann das Laborbuch als Nachschlagewerk in Diskussionen eingesetzt werden.
Im Projekt mit EnBW haben wir das Laborbuch als eine Wikiseite im Projektwiki des Teams umgesetzt. Die Einträge auf der Seite haben wir absteigend chronologisch sortiert, d.h. das Wissen aus den aktuellen Spikes stand ganz oben. Wir haben das Laborbuch ca. ein Jahr lang angewendet und konnten in dieser Zeit keinerlei Skalierungsprobleme wahrnehmen. Das Laborbuch genoss als Wissensquelle im Team ein hohes Ansehen und wurde regelmäßig in Diskussionen eingesetzt.
Kommen wir nun zu unserer letzten Empfehlung: einer konkreten Definition von DoR und DoD für Spikes, die auf die beiden vorigen Good Practices abgestimmt ist.
Die DoR legt fest, welche Kriterien Spikes erfüllen müssen, bevor sie in einen Sprint aufgenommen und bearbeitet werden können. Wie erwähnt ist die DoR nicht Teil von Scrum, sondern eine häufig genutzte Erweiterung. Manche Scrum Experten sehen die DoR kritisch, weil sie dazu führen kann, dass wichtige BLIs aus „Schönheitsgründen“ nicht in einen Sprint aufgenommen werden10. Wir schlagen deshalb einen Kompromiss vor: wichtige BLIs werden immer in den nächsten Sprint aufgenommen, aber die bearbeitende Person ist dafür verantwortlich, dass das BLI vor der Bearbeitung die DoR erfüllt. Das heißt, die Erfüllung der DoR-Kriterien ist der erste Arbeitsschritt jedes BLIs.
Unser Vorschlag der DoR für Spikes ist simpel: vor Bearbeitung eines Spikes muss der Laborbucheintrag des Spikes möglichst präzise vorausgefüllt werden. Insbesondere müssen die zu untersuchenden Hypothesen klar aufgelistet werden. Im Team mit EnBW haben wir gute Erfahrungen damit gemacht, dass ein Teammitglied vor Bearbeitung des Spikes selbst die Hypothesen formuliert und diese dann von einem anderen Teammitglied kritisch prüfen lässt. Wenn die Hypothesen vollständig, verständlich und klar definiert sind, kann die Bearbeitung des Spikes beginnen.
Der Laborbucheintrag gibt dem Spike einen Rahmen vor. Das ist vergleichbar zum bekannten test-driven development (TDD)in der Softwareentwicklung. Dort wird zuerst mit Unit Tests definiert, was die Software leisten soll, danach wird sie implementiert. Die Erstellung eines Laborbucheintrags vor jedem Spike könnte man analog als hypothesis-driven learning (HDL)bezeichnen: zuerst wird mit Hypothesen definiert, was gelernt werden soll, danach werden die Hypothesen untersucht.
Die Analogie zwischen TDD und HDL eignet sich auch um die Vorteile von HDL zu beschreiben. Genauso wie TDD einen stetigen Anreiz zur Reduktion der Softwarekomplexität setzt, setzt HDL einen Anreiz für einfache und zielgerichtete Experimente. Und genauso wie programmierte Tests in TDD einen Großteil der schriftlichen Dokumentation einer Software ersetzen, so ersetzen die Laborbucheinträge in HDL einen Großteil der schriftlichen Dokumentation des Wissens aus Spikes.
Mindestens so wichtig wie die DoR ist die DoD eines Spikes. Sie legt fest, welche Kriterien erfüllt sein müssen, damit der Spike abgeschlossen ist. Auch diese Kriterien lassen sich am Laborbucheintrag des Spikes festmachen. Konkret schlagen wir vor, dass ein Spike fertig ist, wenn alle im Laborbucheintrag gelisteten Hypothesen bestätigt oder verworfen sind, der Laborbucheintrag geschrieben ist und die Ergebnisse im Team kommuniziert wurden.
In diesem Blog-Post haben wir einen konkreten Vorschlag gemacht, wie man Spikes in R&D Scrum Projekten einsetzen sollte. Unser Vorschlag befähigt ein R&D Scrum Team dazu, die Realisierbarkeit von innovativen Produkteigenschaften einzuschätzen – rechtzeitig vor der Umsetzung des Produkts und mit angemessenem Aufwand.
Kern unseres Vorschlags sind zwei Good Practices, die sich in unseren eigenen R&D Scrum Projekten bewährt haben: erstens, ein Regeltermin zur Spike-Pflege und zweitens,ein leichtgewichtiges Laborbuch zur Protokollierung von Erkenntnissen. Wir haben gezeigt, wie sich beide Praktiken mithilfe einer simplen DoR und DoD in Scrum einbinden lassen.
Mit den beiden Good Practices befüllen wir eine Lücke in der Scrum Literatur: es gibt bisher kaum konkrete Praktiken zur Erstellung, Priorisierung, Qualitätssicherung und Langzeitverwertung von Spikes. Die vorgeschlagenen Good Practices sind simpel und allgemein genug, um für die meisten R&D Scrum Teams anwendbar und nützlich zu sein. Wir freuen uns, wenn sich andere Scrum Teams davon inspirieren lassen.
https://www.scieneers.de/wp-content/uploads/2025/02/as.png10241024Nico Kreilinghttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngNico Kreiling2025-03-07 09:06:552025-03-14 12:57:03Mit Scrum erfolgreich sein in Forschung und Entwicklung
Microsoft Fabric ist eine vielseitige und leistungsstarke Plattform für aktuelle Daten- und Analyseanforderungen und genießt derzeit große Aufmerksamkeit bei unseren Kunden. Dabei begegnen wir ganz unterschiedlichen Bedürfnissen – abhängig von Unternehmensgröße, Datenkultur und dem jeweiligen Entwicklungs- und Analysefokus.
Kunden aus dem Power-BI-Umfeld profitieren insbesondere von der Erweiterung des Self-Service-Ansatzes: Über vertraute Weboberflächen und ohne spezialisierte Entwicklungsprogramme können selbst Fachabteilungen oder Enduser schnell in die Datenaufbereitung einsteigen.
Erfahrene Entwickler:innen und IT-Teams möchten hingegen sicherstellen, dass sie in Fabric nicht auf bewährte Abläufe, wie die Entwicklung in einer IDE, Versionsverwaltung via Git oder etablierte Test- und Rollout-Prozesse, verzichten müssen. Dabei stellt sich die Frage, wie zentrale Änderungen robust geprüft und einer Vielzahl von Usern zur Verfügung gestellt werden können.
In diesem Blogpost möchten wir einen Überblick über die Entwicklungs- und Kollaborationsmöglichkeiten sowie die verschiedenen Deployment-Szenarien in Fabric geben. Obwohl wir versuchen, einen allgemeinen Überblick darzustellen, arbeitet Microsoft aktuell mit Hochdruck an neuen Funktionen und Verbesserungen für Fabric, sodass sich technische Einzelheiten mit der Zeit ändern können. Der jeweils aktuelle Stand zur Entwicklung von Fabric ist in der offiziellen Dokumentation oder im Microsoft-Fabric-Blog zu finden.
Fabric als Software-as-a-Service wird in der Regel direkt über den Browser bedient.
Wer bereits den Power BI Service kennt, findet sich dank des vertrauten Workspace-Konzepts sofort zurecht. Neue Fabric-Objekte wie Dataflows oder Data Pipelines lassen sich unkompliziert in der Weboberfläche erstellen und bearbeiten – eine lokale Entwicklungsumgebung oder zusätzliche Softwareinstallationen sind dafür nicht nötig.
Ein weiterer wesentlicher Vorteil der browserbasierten Entwicklung in Fabric ist die plattformunabhängige Nutzbarkeit unter Windows und macOS. Allerdings sind Entwicklungsumgebung im Browser allgemein weniger flexibel und anpassbar als eine vollständige Entwicklungsumgebung (IDE), da nur ein eingeschränkter Umfang an Tools und Integrationsmöglichkeiten zur Verfügung steht. Das ist auch in Bezug auf Fabric der Fall.
Änderungen an Fabric-Objekten sind sofort live und können direkt von anderen Usern gesehen und getestet werden, wodurch sich die Entwicklungszyklen deutlich beschleunigen. Allerdings bringt diese unmittelbare Sichtbarkeit auch Risiken mit sich: Fehler oder ungewollte Änderungen wirken sich sofort auf alle User aus und lassen sich nicht so einfach rückgängig machen wie in lokal gespeicherten Dateien.
Aus diesem Grund arbeitet Microsoft an einer integrierten Versionierung, inklusive Rollback-Funktionalität für verschiedene Fabric-Objekte. Für Notebooks ist diese Funktion bereits verfügbar, für semantische Modelle befindet sie sich aktuell in der Preview-Phase.
Trotz einiger Einschränkungen bei Flexibilität und Tool-Integration bietet die Weboberfläche damit einen schnellen, bequemen Einstieg in die Entwicklung und vereinfacht die Zusammenarbeit in verteilten Teams. Beispielsweise unterstützt die Notebook-GUI paralleles Arbeiten, einschließlich Kommentaren und Cursor-Highlighting, was Pair Programming, Remotedebugging oder auch Tutoren-Szenarien erleichtert.
Dieser Entwicklungsprozess ist vor allem für Szenarien geeignet, in denen eine isolierte Entwicklung nicht erforderlich ist und Änderungen direkt am Live-Stand vorgenommen werden können – beispielsweise für Enduser in nicht-technischen Fachabteilungen oder weniger kritische Anwendungsfälle.
Benötigt man hingegen eine dedizierte Umgebung, um neue Funktionen oder Anpassungen zu testen, ohne den Live-Stand zu beeinflussen, stehen grundsätzlich zwei Ansätze zur Verfügung.
2. Isolierte Entwicklung mittels lokaler Client-Tools
Für verschiedene Fabric-Objekte stehen Client-Tools zur Verfügung, die auf einem Rechner installiert werden können und mit denen sich diese Objekte lokal bearbeiten lassen. Meist wird dazu eine lokale Kopie des Fabric-Objekts erzeugt, diese wird bearbeitet und nach Fertigstellung aller Änderungen wieder in den Fabric Workspace hochgeladen.
Power-BI-User kennen diesen Ablauf bereits: Ein Power-BI-Report aus Fabric kann als .pbix-Datei heruntergeladen und mit Power BI Desktop lokal bearbeitet werden. Die Änderungen am Report werden in Fabric erst sichtbar, wenn man die lokalen Änderungen veröffentlicht. Vergleichbar läuft das Bearbeiten von Fabric-Notebooks ab, welche als .ipynb-Datei exportiert und lokal mit den präferierten Entwicklungstools bearbeitet werden können. Für VS Code gibt es eine Erweiterung (derzeit noch unter dem Namen „Synapse“) die diesen Prozess vereinfacht.
Hat man diese VS-Code-Erweiterung installiert, kann man direkt über einen Button in der Fabric-GUI eine lokale Kopie des gewünschten Notebooks erzeugen und in VS Code öffnen.
So arbeitet man in einer gewohnten Entwicklungsumgebung. Bei Bedarf kann man den Code über die fabric-spark-runtime sogar auf der Fabric-Kapazität ausführen lassen und damit große Datenmengen verarbeiten. Sobald alle Änderungen am Notebook erfolgt sind, lädt man die angepasste Version einfach wieder über das VS-Code-Plugin in den Fabric Workspace hoch – inklusive praktischer Diff-Funktion, um Unterschiede gegenüber der Version im Fabric Workspace anzuzeigen.
Darüber hinaus kann auch in anderen Bereichen mit lokalen Tools auf die Fabric-Umgebung zugegriffen werden. Beispielsweise lassen sich VS Code oder SQL Server Management Studio verwenden, um SQL-Abfragen zu schreiben oder Views zu definieren. Besonders das Fabric Warehouse ist aktuell gut in diese Tools integriert, eine Verbindung ist grundsätzlich aber mit allen SQL-basierten Fabric-Objekten möglich.
Die vorgestellten Funktionen sind ohne eine Anbindung des Fabric-Workspaces an ein Git-Repository nutzbar. Damit eignet sich dieser Prozess besonders für User, die eine isolierte Entwicklungsumgebung benötigen, jedoch noch keine Erfahrung mit Git haben oder deren Workspaces aus organisatorischen Gründen (noch) nicht an ein Git-Repository angebunden sind.
Für erfahrene Entwickler:innen ist eine Git-Integration jedoch ein zentraler Baustein professioneller Entwicklungsprozesse. Aus diesem Grund bietet Microsoft Fabric auch eine native Integration in Azure DevOps und GitHub.
Einschub: Fabric Git-Integration
Microsoft Fabric ermöglicht es, einen Workspace mit einem Azure DevOps- oder GitHub-Repository zu verbinden, um die Vorteile eines Git -integrierten Entwicklungsprozesses, wie beispielsweise die Versionierung, zu nutzen. Eine ausführliche Erläuterung aller Funktionen und Einschränkungen dieser Funktionalität findet sich hier.
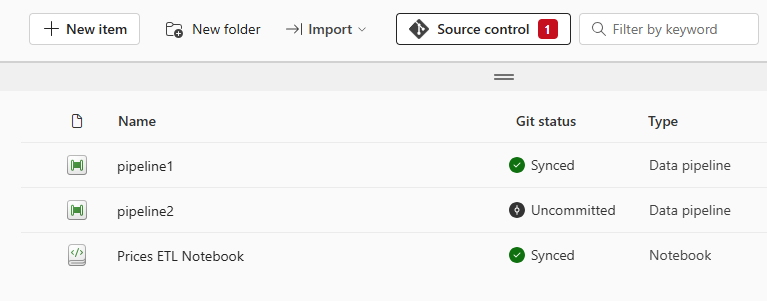
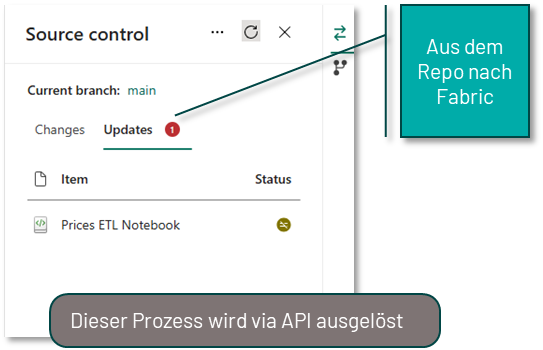
Ist ein Workspace an ein Repository angebunden, kann jederzeit der Git-Status der einzelnen Fabric-Objekte eingesehen werden. Änderungen an Objekten oder das Erstellen neuer Objekte können direkt aus der GUI heraus committet und in dem Repository gespeichert werden. Dadurch ist sicher gestellt, dass versehentlich gelöschte Objekte jederzeit wiederhergestellt werden können.
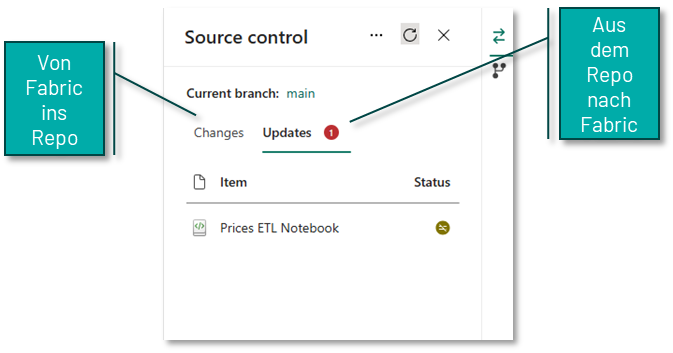
Es ist wichtig zu verstehen, dass diese Synchronisation zwischen Fabric und dem Repository in beide Richtungen erfolgen kann. Es können also Änderungen aus Fabric in das Repository gesichert werden und ebenso Änderungen an den Objekten im Repository (z.B. wenn ein Notebook direkt im Repository bearbeitet wurde) zurück in den Fabric Workspace importiert werden.
Wenn der Fabric Workspace Git-integriert ist, eröffnet das weitere Möglichkeiten, lokal mit verschiedenen Fabric-Elementen zu arbeiten. Durch das Klonen des entsprechenden Repositories kann man alle bekannten Git-Features nutzen, wie zum Beispiel lokale Feature-Branches oder einzelne Commits für wichtige Zwischenstände.
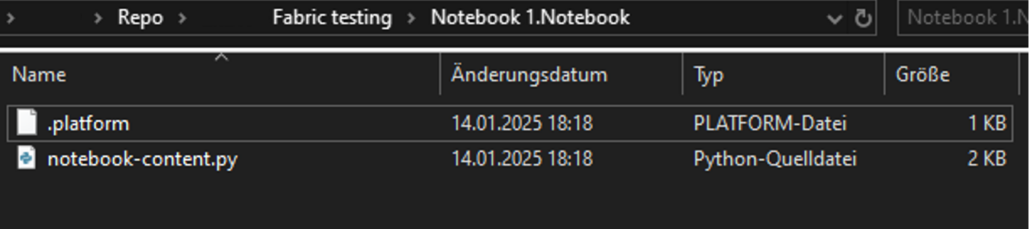
Ein Nachteil dabei ist jedoch, dass einzelne Fabric-Objekte im Repository in Formaten gespeichert werden, die primär auf eine Git-optimierte Speicherung und nicht auf eine komfortable Bearbeitung ausgelegt sind. Notebooks werden beispielsweise nicht als .ipynb-Dateien gespeichert, sondern als reine .py-Dateien, ergänzt durch eine zusätzliche .platform-Datei, die wichtige Metadaten enthält. Das kann das lokale Arbeiten mit Branches im Repository erschweren.
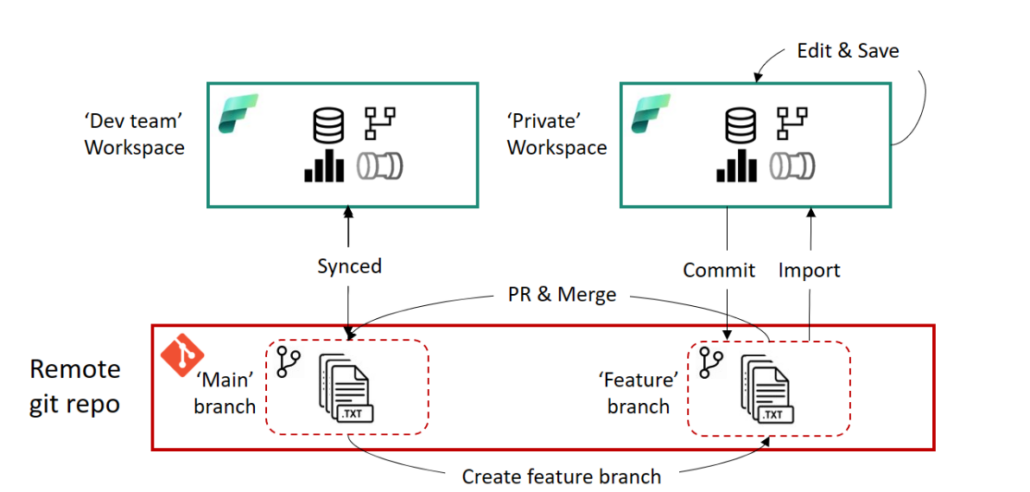
3. Isolierte Entwicklung in Feature-Branch Workspaces
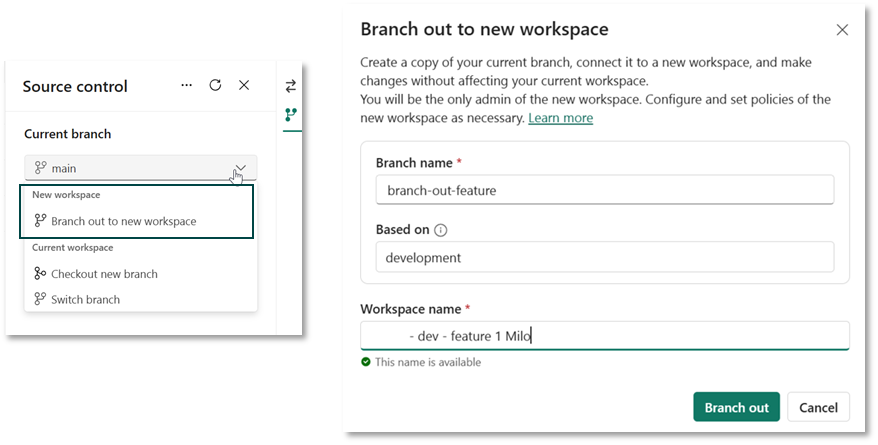
Um eine isolierte Entwicklungsumgebung zu erreichen, muss man in Fabric nicht zwangsläufig auf lokale Tools ausweichen. Fabric bietet – vorausgesetzt, der Workspace ist Git-integriert – auch native Möglichkeiten. Besonders interessant ist hierbei die Funktion “Branch out to a new feature-workspace”, die hier näher beschrieben wird.
Nutzt man dieses Feature, wird eine Kopie des Workspaces erstellt, auf den zunächst nur man selber Zugriff hat. In diesem kann man isoliert entwickeln, ohne die Funktionalität der Objekte im eigentlichen Workspace zu beeinflussen. Im Hintergrund passiert Folgendes:
Es wird ein neuer, leerer Workspace mit dem definierten Namen angelegt.
In diesen Branch wird der Inhalt des aktuellen Workspaces kopiert.
Im Repository wird ein neuer Branch angelegt, dessen Namen ebenfalls bestimmt werden kann.
Im neu angelegten Workspace werden die Fabric-Objekte basierend auf dem neu angelegten Branch erstellt.
Man kann nun isoliert an den Fabric-Objekten arbeiten und die Änderungen in den neuen Branch committen, beispielsweise wenn man an einem Notebook weiterentwickeln möchte. Wichtig hierbei ist, dass Daten (z.B. in einem Lakehouse) nicht im Repository gespeichert werden und somit auch nicht in dem neuen Workspace zur Verfügung stehen. Das bedeutet, ein Notebook verbindet sich weiterhin mit dem Lakehouse in dem eigentlichen Workspace, wenn dieses im Notebook als Datenquelle genutzt wurde.
Hat man alle Änderungen in dem Feature-Workspace durchgeführt, muss man diese Änderungen noch zurück in den eigentlichen Workspace übertragen. Dieser Prozess erfolgt primär in Azure DevOps bzw. GitHub und setzt ein grundlegendes Verständnis von Git voraus. Man erstellt hierfür einen Pull-Request (PR), um den Feature-Branch in den Main-Branch des eigentlichen Workspaces zu mergen. Hierbei stehen alle gewohnten Funktionalitäten von DevOps und GitHub zur Verfügung, wie z.B. das Taggen von Reviewern. Ist der PR erfolgreich abgeschlossen, hat der Main-Branch im Repository einen aktuelleren Stand als die Fabric-Objekte im Workspace selbst. Abschließend muss der Stand aus dem Repository also noch in den Workspace übertragen werden. Hierfür kann man den oben beschriebenen Prozess des Updates im Source Control Panel des Fabric Workspaces nutzen oder diesen Prozess via API automatisieren.
Das folgende Diagramm veranschaulicht diesen Prozess.
Dieser Entwicklungsprozess bietet die umfassenden Vorteile einer Git-basierten Entwicklung und lässt sich bei Bedarf zusätzlich mit lokalen Client-Tools ergänzen. So ist es beispielsweise möglich, die Notebooks im Feature-Workspace über den oben beschriebenen Prozess in VS Code zu öffnen.
Dennoch bringt dieser Prozess auch einige Nachteile mit sich. Da Pull-Requests und Merges in Azure DevOps bzw. GitHub durchgeführt werden, setzt dieser Prozess Erfahrung im Umgang mit Git sowie Azure DevOps oder GitHub voraus. Außerdem müssen User, die dieses Feature in Fabric nutzen möchten, die Berechtigung haben, Workspaces zu erstellen, was zunächst von einem Administrator freigegeben werden muss. Zum aktuellen Zeitpunkt werden die Feature-Workspaces zudem nicht automatisch gelöscht, nachdem ein erfolgreicher Merge in den Ausgangs-Workspace durchgeführt wurde. Dies kann dazu führen, dass sich im Laufe der Zeit einige nicht mehr benötigte Workspaces ansammeln, wenn diese nicht manuell gelöscht werden.
Deployment Prozesse
Ein weiterer Schritt zur Professionalisierung des Einsatzes von Microsoft Fabric besteht darin, Workloads in mehreren Umgebungen bzw. Environments zu betreiben. In der Regel wird zwischen einer Entwicklungsumgebung (Dev.) und einer Produktivumgebung (Prod.) unterschieden. Dies ermöglicht es, den Workload in der Entwicklungsumgebung isoliert und iterativ weiterzuentwickeln, während die Enduser in der Produktivumgebung jederzeit eine funktionierende und gut dokumentierte Version des Workloads vorfinden.
Sobald ein zufriedenstellender Punkt im Entwicklungsprozess erreicht ist, wird der Entwicklungsstand von der Entwicklungsumgebung in die Produktivumgebung übertragen. Dieser Vorgang wird als Deployment-Prozess bezeichnet. Microsoft Fabric bietet hierfür verschiedene Möglichkeiten.
1. Fabric Deployment Pipelines
Die einfachste Möglichkeit, einen Deployment-Prozess in Fabric zu integrieren, sind die sogenannten Fabric Deployment Pipelines. Sie sind fester Bestandteil von Fabric und benötigen kein weiteres Tooling – um sie zu benutzen, muss der Entwicklungs-Workspace nicht einmal mit einem Git-Repository verknüpft sein.
Für jede Umgebung wird ein Workspace angelegt, und anschließend wird in dem Entwicklungs-Workspace eine Deployment Pipeline aufgesetzt. Über ein übersichtliches Interface definiert man, welche Fabric-Objekte vom Ausgangs-Workspace (in der Darstellung unten „Development“) in den Ziel-Workspace (in unserem Fall „Test“) übertragen werden sollen, und klickt auf „Deploy“.
Da sich unterschiedliche Umgebungen in der Regel in ihren Eigenschaften unterscheiden – beispielsweise in der Datenbank, auf die sie zugreifen – lassen sich für jedes Fabric-Objekt sogenannte Deployment-Rules definieren. Diese stellen sicher, dass diese Eigenschaften während des Deployment-Prozesses entsprechend angepasst werden.
Zum aktuellen Zeitpunkt sind diese Deployment-Rules jedoch noch nicht für alle Fabric-Objekte einsetzbar und unterstützen nur eine vordefinierte Auswahl an Eigenschaften, die angepasst werden können. So kann man beispielsweise in einem Fabric-Notebook keine zuvor im Code definierten Parameterwerte austauschen.
Insgesamt bieten die Fabric Deployment Pipelines einen einfachen Einstieg in die Entwicklung mit mehreren Umgebungen, ohne dass tiefgreifende Erfahrung mit Git notwendig ist. Sie eignen sich besonders für Workloads, die beispielsweise von nicht-technischen Fachabteilungen verwaltet werden, und stellen eine logische Erweiterung des Self-Service-Prinzips dar.
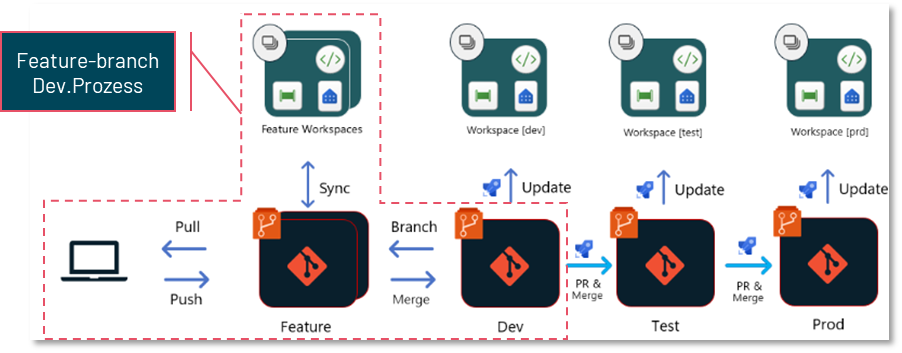
2. Branch-based Deployment
Die zweite Möglichkeit, einen Deployment-Prozess in Fabric umzusetzen, erfordert, dass alle Workspaces, die eine bestimmte Umgebung darstellen (z.B. Dev., Test. und Prod.), mit verschiedenen Branches desselben Git-Repositories verknüpft sind. Die Funktionsweise des branch-basierten Deployments ähnelt dem Feature-Branch-Entwicklungsprozess, der im folgenden Diagramm gekennzeichnet ist. Grundsätzlich ist der branch-basierte Deployment-Prozess jedoch mit allen Entwicklungsprozessen kombinierbar, solange eine Git-Integration eingerichtet ist.
Dieser Prozess nutzt die Funktionalität von Azure DevOps Pipelines (bzw. GitHub Actions), die automatisch auf Änderungen in Repository-Branches reagieren und bestimmte Prozesse anstoßen können.
Sobald ein neuer Entwicklungsstand in der Entwicklungsumgebung (Dev.) entwickelt wurde und bereit für das Deployment ist, wird im Repository ein Pull-Request (PR) in einen Test-Branch eröffnet. In diesem Branch können Reviewer die neuen Änderungen überprüfen und freigeben.
Nach der Freigabe und Aktualisierung des Test-Branches wird automatisch eine DevOps-Pipeline gestartet, die verschiedene Aktionen auf den Objekt-Definitionen in diesem Branch ausführt. Diese Pipeline kann beispielsweise Umgebungsparameter (wie Datenbankverbindungen) anpassen, automatisierte Tests auf dem Code durchführen oder sicherstellen, dass der Code den Stil- und Benennungskonventionen entspricht.
Der angepasste Code wird dann in einem weiteren Branch, wie z.B. Test-Release, gespeichert. Dieser Test-Release-Branch ist mit dem Test-Workspace in Fabric verbunden. Eine zweite Pipeline reagiert auf die Aktualisierung dieses Branches und sorgt über eine API dafür, dass der Stand aus diesem Branch in den Fabric-Workspace übertragen wird.
Im Test-Workspace können anschließend direkt in Fabric weitere Tests, wie Data-Quality-Tests, durchgeführt werden, bevor der Code über einen analogen Prozess in den produktiven Workspace übertragen wird.
Diese Form des Deployment-Prozesses erfordert neben dem Verständnis von Git auch Erfahrung im Aufsetzen von Azure DevOps Pipelines bzw. GitHub Actions und ist daher für erfahrene Entwickler:innen und kritische Workloads konzipiert. Die Verwendung professioneller Deployment-Tools bietet dann jedoch die volle Flexibilität in der Ausgestaltung des Deployment-Prozesses und der Integration erweiterter Schritte wie Code-Testing.
Die Arbeit mit dedizierten Branches pro Umgebung erlaubt außerdem das einfache Handling verschiedener Versionen in den einzelnen Umgebungen sowie das schnelle Zurückrollen auf vorherige Stände.
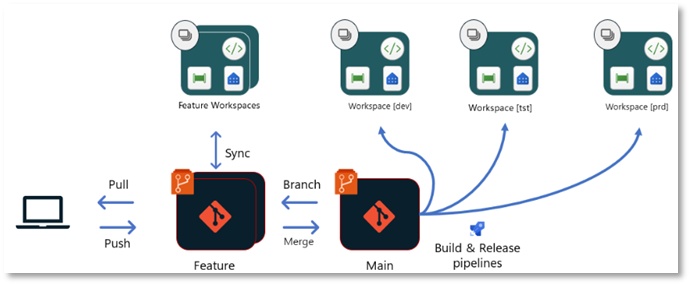
3. Release-Pipeline Deployment
Eine weitere Möglichkeit für ein Deployment in Fabric besteht darin, die einzelnen Workspaces nicht direkt über die integrierten Möglichkeiten mit einem Branch in einem Repository zu verbinden, sondern ausgehend von einem geteilten Main-Branch über Build- und Release-pipelines direkt in die einzelnen Workspaces zu deployen.
Bei diesem Ansatz kann – wie im vorherigen Prozess auch – eine Build-Pipeline je nach Zielumgebung Umgebungsparameter (wie Datenbankverbindungen) austauschen, automatisierte Tests auf dem Code durchführen oder sicherstellen, dass der Code den Stil- und Benennungskonventionen entspricht. Das Ergebnis wird in diesem Ansatz jedoch nicht in einem eigenen Branch gespeichert, sondern beispielsweise als Artefakt an eine Release-Pipeline übergeben. Diese nutzt dann die Fabric Item API, um die jeweiligen Fabric-Objekte oder Änderungen in den Ziel-Workspace zu deployen.
Um die Interaktion mit der Fabric API zu vereinfachen, können Libraries wie die fabric-cicd Python Library verwendet werden.
Genau wie das Branch-based Deployment erfordert dieser Ansatz Erfahrung im Umgang mit Azure DevOps Pipelines, erlaubt deshalb aber auch die volle Flexibilität in der genauen Ausgestaltung des Deploymentprozesses.
Fazit
In diesem Artikel haben wir die gängigsten Entwicklungs- und Deploymentprozesse in Microsoft Fabric exemplarisch vorgestellt. Gerade innerhalb der Deploymentprozesse über Azure DevOps bzw. Github besteht in der konkreten Ausgestaltung aber natürlich die volle Flexibiltät, diese genau auf die eigenen Bedürfnisse anzupassen. Es ist außerdem nicht notwendig sich bei allen Workloads, die auf Fabric abgebildet werden sollen, für einen einzigen Entwicklungs- oder Deploymentprozess zu entscheiden. Die Wahl des passenden Prozesses sollte stets auf die spezifischen Anforderungen und den jeweiligen Workload abgestimmt sein. So ist es sinnvoll einen professionellen Deploymentprozess für zentrale Datenprodukte wie z.B. ein unternehmensweites Datawarehouse zu wählen, während für einzelne Fachbereiche evtl. ein Deployment über Deployment Pipelines ausreicht, oder sogar komplett auf Deploymentprozesse verzichtet werden kann.
Wer noch mehr Tipps und Tricks zu Microsoft Fabric erfahren möchte, sollte einen Blick in unseren Microsoft Fabric Kompakteinführung Workshop werfen!
Verbreiter:innen von Desinformation nutzen verschiedene Strategien, um falsche Aussagen authentisch wirken zu lassen. Um effektiv dagegen vorzugehen und die Glaubwürdigkeit solcher Desinformationen zu mindern, ist es entscheidend, dass die Betroffenen nicht nur die Desinformation als solche erkennen, sondern auch die verwendeten irreführenden rhetorischen Strategien durchschauen.
In unserer heutigen Zeit ist dies wichtiger denn je: Ob in sozialen Medien oder bei Familienfeiern, täglich sind wir einer Flut von Informationen und Meinungen ausgesetzt. Oftmals entscheiden wir in Bruchteilen von Sekunden, ob wir diese als wahr oder fragwürdig einstufen. Die Kenntnis häufig verwendeter rhetorischer Strategien stärkt die Intuition und fördert kritisches Hinterfragen bei zweifelhaften Argumentationen.
Aus diesem Grund haben wir den DesinfoNavigator entwickelt – ein Tool, das Menschen dabei unterstützt, Desinformationen zu erkennen und zu entkräften. Mit dem DesinfoNavigator können Nutzer:innen Textauszüge auf irreführende rhetorische Strategien prüfen und erhalten zugleich Anleitungen, wie sie die Textstellen bezüglich dieser Strategien untersuchen können.
Für die Analyse dieser Strategien verwenden wir im DesinfoNavigator das PLURV-Framwork, welches folgende fünf Kategorien umfasst: Pseudo-Expert:innen, logische Trugschlüsse, unerfüllbare Erwartungen, Rosinenpickerei und Verschwörungsmythen.
In der technischen Umsetzung nutzt der DesinfoNavigator ein großes Sprachmodell (engl. Large Language Model, LLM). Im ersten Schritt analysiert das Tool die Eingaben der Nutzer:innen auf mögliche rhetorische Strategien gemäß des PLURV-Frameworks. Dabei erhält das Sprachmodell neben der Nutzereingabe auch eine detaillierte Beschreibung der Strategien inklusive Beispiele. Als Resultat liefert das Modell Textstellen, bei denen Hinweise auf eine der Strategien vorliegen. Im zweiten Schritt generiert das Sprachmodell für jede identifizierte Textstelle eine Handlungsanweisung, die Anleitungen gibt, wie man die Textstelle hinsichtlich der Strategie überprüfen kann.
Es ist wichtig zu betonen, dass der DesinfoNavigator keine klassischen Faktenchecks durchführt; er analysiert vielmehr, ob und welche rhetorischen Strategien möglicherweise in einem Text verwendet werden. Wir verstehen den DesinfoNavigator somit als logische Ergänzung zu bisher existierenden Faktenchecking-Tools.
Um den größtmöglichen gesellschaftlichen Nutzen zu erzielen, haben wir uns dazu entschieden, den DesinfoNavigator kostenlos und frei zugänglich zu machen. Dies ermöglicht es einem breiten Publikum, sich aktiv mit der Erkennung und Bekämpfung von Desinformation auseinanderzusetzen.
Neugierig geworden? Der DesinfoNavigator kann aktuell unter https://desinfo-navigator.de/ ausprobiert werden. Wir freuen uns über hilfreiche Rückmeldungen sowie über interessierte Kooperationspartner:innen, die uns helfen möchten, den DesinfoNavigator weiterzuentwickeln und einer breiteren Öffentlichkeit zugänglich zu machen.
Indem wir den DesinfoNavigator kontinuierlich weiterentwickeln und verbessern, streben wir danach, einen bedeutenden Beitrag im Kampf gegen die Verbreitung von Desinformation zu leisten. Unser Ziel ist es, ein stärkeres Bewusstsein für einen kritischen Umgang mit der alltäglichen Informationsflut zu schaffen und zu fördern.
Autoren
Dr. Clara Christner
Kommunikationswissenschaftlerin mit Forschungsschwerpunkt Desinformationen