

KI trifft Datenschutz: Unsere ChatGPT-Lösung für Unternehmenswissen
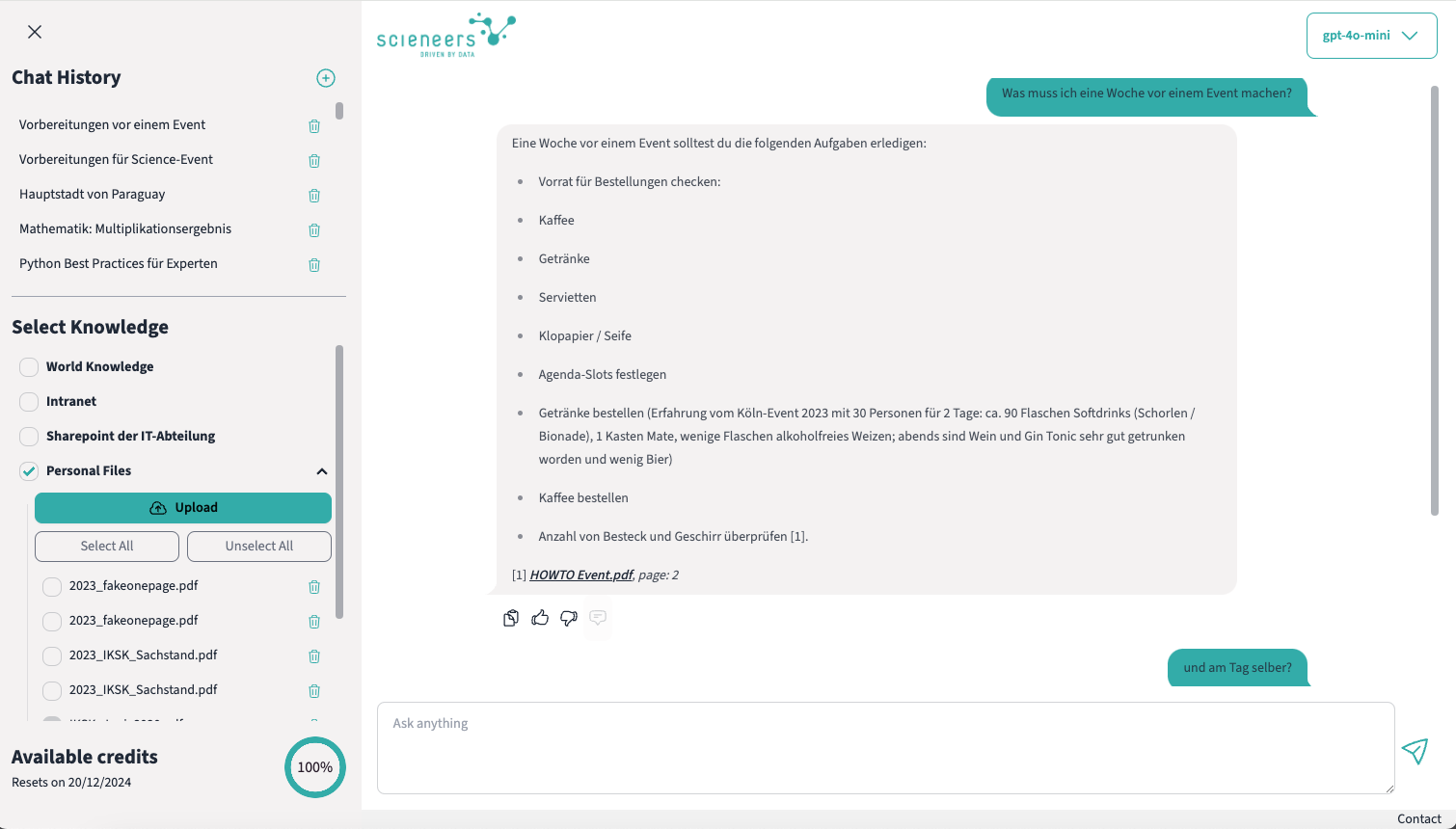
Jeder kennt ChatGPT – ein Chatbot, der Antworten auf fast jede Frage liefert. Doch in vielen Firmen ist die Nutzung offiziell noch nicht erlaubt oder wird nicht bereitgestellt. Dabei kann ChatGPT komplett datenschutzkonform und sicher betrieben werden und Mitarbeitenden einen einfachen Zugang zu internem Firmenwissen ermöglichen. Basierend auf Erfahrungen aus zahlreichen Retrieval-Augmented Generation (RAG)-Projekten haben wir ein modulares System entwickelt, das speziell auf die Bedürfnisse mittelständischer Unternehmen und Organisationen zugeschnitten ist. In diesem Beitrag stellen wir unseren leichtgewichtigen und anpassbaren Chatbot vor, der einen datenschutzkonformen Zugriff auf Unternehmenswissen ermöglicht.
1. Eigene Wissensquellen nutzen
Der Kern unseres RAG-Systems liegt darin, dass ein LLM auf die unternehmensspezifische Wissensquellen zugreifen kann. Dem Chatbot können verschiedene Datenquellen zur Verfügung gestellt werden:
1. Nutzerspezifische Dokumente:
- Mitarbeitende können eigene Dateien hochladen, z. B. PDF-Dokumente, Word-Dateien, Excel-Tabellen oder sogar Videos. Diese werden im Hintergrund verarbeitet und stehen nach kurzer Zeit dauerhaft zum Chatten zur Verfügung.
- Der Verarbeitungsstatus ist jederzeit einsehbar, damit transparent bleibt, wann die Inhalte für Anfragen genutzt werden können.
- Beispiel: Ein Vertriebsmitarbeitender lädt eine Excel-Tabelle mit Preisinformationen hoch. Das System kann daraufhin Fragen zu den Preisen spezifischer Produkte beantworten.
2. Globale unternehmensinterne Wissensquellen:
- Das System kann auf zentrale Dokumente aus Plattformen wie SharePoint, OneDrive oder dem Intranet zugreifen. Diese Daten sind für alle Nutzenden zugänglich.
- Beispiel: Ein Mitarbeitender möchte nach den Regelungen zur betrieblichen Altersvorsorge suchen. Da die entsprechende Betriebsvereinbarung zugänglich ist, kann der Chatbot die korrekte Antwort geben.
3. Gruppenspezifische Wissensquellen:
- Es ist auch möglich, dass Informationen / Dokumente nur für spezifische Teams oder Abteilungen zugänglich gemacht werden.
- Beispiel: Nur das HR-Team hat Zugriff auf Richtlinien zum Onboarding. Das System kann Fragen dazu nur HR-Mitarbeitenden beantworten.
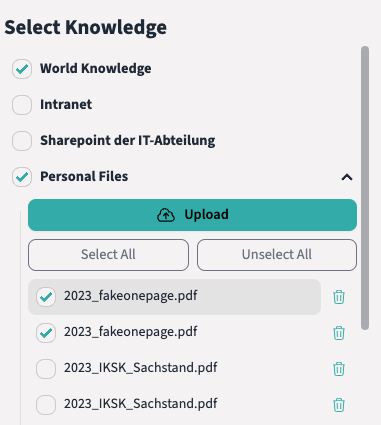
Auch wenn Nutzende mit allen verfügbaren Datenquellen arbeiten, stellt das System im Hintergrund sicher, dass nur für eine Anfrage relevante Informationen genutzt werden, um Antworten zu generieren. Durch intelligente Filtermechanismen werden irrelevante Inhalte automatisch ausgeblendet.
Nutzende haben jedoch die Möglichkeit, explizit festzulegen, welche Wissensquellen berücksichtigt werden sollen. Sie können beispielsweise wählen, ob eine Anfrage auf aktuelle Quartalszahlen oder auf allgemeine HR-Richtlinien zugreifen soll. Dadurch wird vermieden, dass irrelevante oder veraltete Informationen in die Antwort einfließen.
2. Feedback-Prozess und kontinuierliche Verbesserung
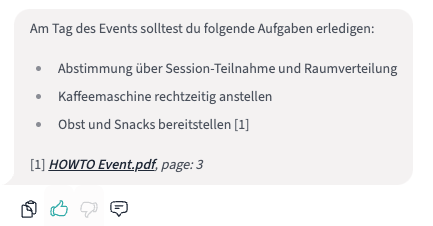
Ein zentraler Bestandteil unserer RAG-Lösung ist die Möglichkeit, systematisch Feedback der Nutzenden zu erfassen, um die Qualität des Systems verbessern zu können, indem Schwachstellen identifiziert werden. Eine Schwachstelle könnten beispielsweise Dokumente mit uneinheitlichem Format darstellen, wie schlecht gescannte PDFs oder Tabellen mit mehreren verschachtelten Ebenen, die fehlerhaft interpretiert werden.
Nutzende können leichtgewichtig zu jeder Nachricht Feedback geben, indem sie die “Daumen hoch/runter”-Icons nutzen und einen optionalen Kommentar hinzufügen. Dieses Feedback kann entweder von Admins manuell ausgewertet oder durch automatisierte Analysen verarbeitet werden, um gezielt Optimierungspotenziale im System zu identifizieren.
3. Budgetmanagement – Kontrolle über Nutzung und Kosten
Die datenschutzkonforme Nutzung von LLMs im Zusammenhang mit eigenen Wissensquellen bietet Unternehmen enorme Möglichkeiten, bringt aber zugegebenermaßen auch Kosten mit sich. Ein durchdachtes Budgetmanagement hilft, Ressourcen fair und effizient zu nutzen und Kosten im Blick zu behalten.
Wie funktioniert das Budgetmanagement?
- Individuelle und gruppenbasierte Budgets: Es wird festgelegt, wie viel Budget einzelnen Mitarbeitenden oder Teams in einem bestimmten Zeitraum zur Verfügung stehen. Dieses Budget muss nicht zwangsläufig ein Euro-Beitrag sein, sondern kann auch in eine virtuelle eigene Währung umgerechnet werden.
- Transparenz für Nutzende: Alle Mitarbeitenden können jederzeit ihren aktuellen Budgetstatus einsehen. Das System zeigt an, wie viel des Budgets bereits verbraucht wurde und wie viel noch verfügbar ist. Wird das festgelegte Limit erreicht, pausiert der Chat automatisch, bis das Budget zurückgesetzt oder angepasst wird.
4. Sichere Authentifizierung – Schutz für sensible Daten
Ein wesentlicher Aspekt für Unternehmen ist oftmals die sichere und flexible Authentifizierung. Da RAG-Systeme oft mit sensiblen und vertraulichen Informationen arbeiten, ist ein durchdachtes Authentifizierungskonzept unverzichtbar.
- Authentifizierungssysteme: Unsere Lösung ermöglicht die Anbindung unterschiedlicher Authentifizierungsverfahren, darunter weit verbreitete Systeme wie Microsoft Entra ID (ehemals Azure Active Directory). Dies bietet den Vorteil, bestehende Unternehmensstrukturen für die Nutzerverwaltung nahtlos einzubinden.
- Zugriffskontrolle: Unterschiedliche Berechtigungen können auf Basis von Nutzerrollen definiert werden, z. B. für den Zugriff auf bestimmte Wissensquellen oder Funktionen.
5. Flexible Benutzeroberfläche
Unsere aktuelle Lösung vereint die meistgefragten Frontend-Features aus verschiedenen Projekten und bietet damit eine Benutzeroberfläche, die individuell anpassbar ist. Funktionen können bei Bedarf ausgeblendet oder erweitert werden, um spezifische Anforderungen zu erfüllen.
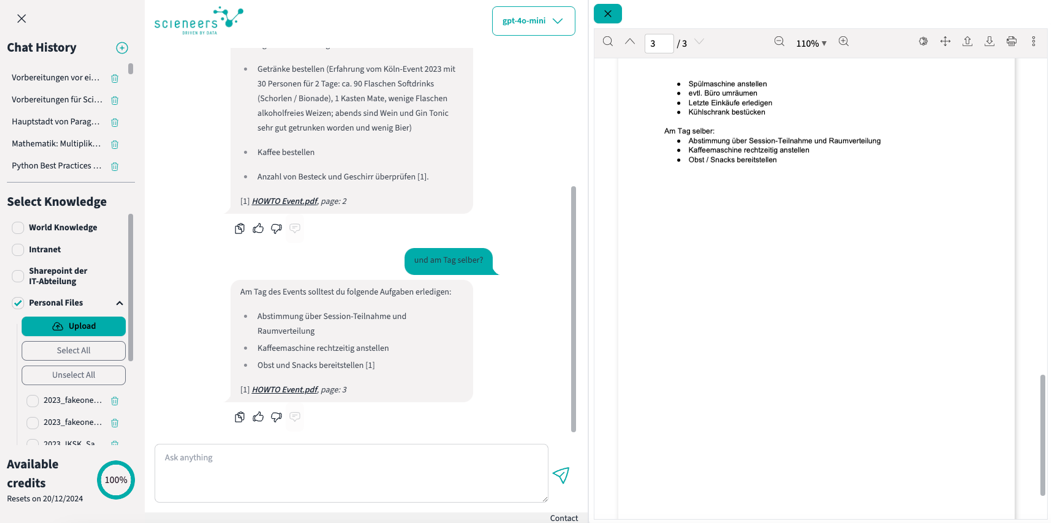
- Chat-Historie: Alle Chats werden automatisch benannt und gespeichert. Auf Wunsch können Nutzende Chats vollständig löschen – dies schließt auch ein endgültiges Entfernen aus dem System ein.
- Zitationen: Zitationen gewährleisten, dass Informationen nachvollziehbar und überprüfbar bleiben. Gerade bei komplexen oder geschäftskritischen Fragen stärkt dies die Glaubwürdigkeit und ermöglicht es Nutzenden, die Richtigkeit und den Kontext der Antworten direkt zu überprüfen. Jede Antwort des Systems enthält Verweise auf die ursprünglichen Dokumentenquellen, beispielsweise mit Links zu der exakten Seite in einem PDF oder Absprung zur ursprünglichen Dokumentenquelle.
- Einfache Anpassung von Prompts: Um die Systemantworten zu steuern, können Prompts über eine benutzerfreundliche Oberfläche angepasst werden – ganz ohne technisches Vorwissen.
- Ausgabe von unterschiedlichen Medientypen: in den Antworten werden unterschiedliche Ausgabeformate, wie Codeblöcke oder Formeln, entsprechend angezeigt.
Fazit: Schneller Start, flexible Anpassung, transparente Kontrolle
Unsere Chatbot-Lösung basiert auf den Erfahrungen aus zahlreichen Projekten und ermöglicht Unternehmen, Sprachmodelle gezielt und datenschutzkonform zu nutzen. Dabei können spezifische interne Wissensquellen wie SharePoint, OneDrive oder individuelle Dokumente effizient eingebunden werden.
Dank einer flexiblen Codebasis kann das System schnell auf unterschiedliche Anwendungsfälle angepasst werden. Funktionen wie die Feedback-Integration, das Budgetmanagement und die sichere Authentifizierung sorgen dafür, dass Unternehmen jederzeit die Kontrolle behalten – über sensible Daten und auch die Kosten. Damit bietet das System nicht nur eine praxisnahe Lösung für den Umgang mit Unternehmenswissen, sondern auch die nötige Transparenz und Sicherheit für eine nachhaltige Nutzung.
Sie sind neugierig geworden? Dann zeigen wir Ihnen in einem persönlichen Gespräch gerne unser System in einer Live-Demo und beantworten Ihre Fragen. Schreiben Sie uns einfach!
Autorin

Alina Dallmann, Data Scieneer bei scieneers GmbH
alina.dallmann@scieneers.de





 scieneers
scieneers
