

Eine Einführung in Multi-Agent-AI mit AutoGen
Nachdem 2023 große Sprachmodelle die Masse erreichten und Retrieval-Augmented-Generation-Use-Cases im Fokus der meisten Anwender lagen, rücken 2024 Agenten deutlicher ins öffentliche Blickfeld. Agenten sind (teil-)autonom arbeitende Instanzen, die es ermöglichen, Chat-Anwendungsfälle flexibler zu gestalten. Soll in einem Chat nicht immer das gleiche Dokumentenarchiv über RAG eingebunden werden, sondern je nach Use-Case unterschiedliche Informationsquellen herangezogen werden, so können Agenten beispielsweise selbstständig entscheiden, welche für eine Abfrage die richtige ist. Es können aber nicht nur Datenbanken bzw. nicht-textuelle Informationen integriert werden, sondern auch jeder IT-Prozess, von der Veröffentlichung von Inhalten auf der Website bis hin zur Erstellung und Ausführung von Softwarecode. Der Fantasie sind bezüglich dessen, was mit generativer KI möglich sein könnte, keine Grenzen gesetzt, doch die praktische Umsetzung stößt schnell auf Herausforderungen in Bezug auf Stabilität und Verlässlichkeit.
Dieser Blog-Post diskutiert, wann mehrere kollaborativ zusammenarbeitende Agenten hilfreich sein können. Er ist der erste einer Serie: In diesem werden die Bausteine eines Multi-Agenten-Systems erklärt sowie deren Umsetzung mit Autogen, der ersten Bibliothek speziell für Multi-Agenten-Setups. Der zweite Teil wird dann auf LangGraph eingehen, die kürzlich erschienene Bibliothek zur Umsetzung von Multi-Agenten-Workflows aufbauend auf die beliebte Bibliothek LangChain.
Wann benötigt man mehrere Agenten
Zunächst sollte klar gestellt werden: Mehrere Agenten helfen nicht, wenn es darum geht, eine einzige Aufgabe besonders gut zu lösen. Ist die Aufgabe hingegen gut in mehrere Teilaufgaben zerteilbar, dann können mehrere, spezialisierte Agenten, die zusammenarbeiten, ein guter Ansatz sein. Wollt ihr beispielsweise Kundenanfragen automatisch beantworten, aber das Modell trifft nicht den Kommunikationsstil des Unternehmens, solltet ihr die Zeit lieber in Fine-Tuning stecken. Wenn für die Beantwortung aber verschiedene Informationsquellen erfragt, zusammengefasst und anschließend nochmal unter Berücksichtigung der Corporate-Communication-Policy validiert werden soll, könnte die Aufteilung auf mehrere Agenten hilfreich sein.
Sprachmodelle wie ChatGPT generieren nicht nur Text, sondern wurden inzwischen auch für Function Calling gefinetuned. Auf diese Art wurde ihnen prinzipiell das Konzept von Funktionsaufrufen erklärt. Allerdings können sie derzeit selbst keine Funktionen direkt aufrufen, sondern sagen lediglich, dass sie eine bestimmte Funktion mit gewissen Parametern aufrufen würden. Die tatsächliche Ausführung der Funktion erfordert dann eine entsprechende Runtime. Kombiniert man diese mit der Intelligenz des Sprachmodells, erhält man einen Agenten, der beispielsweise selbstständig Programmcode erstellen, ausführen und anhand der Fehlermeldungen debuggen kann. Ein solcher Agent ist ein besonders mächtiges Tool, da er im Gegensatz zu einem reinen LLM nicht nur in der Lage ist einen textuellen output zu generieren, sondern darüber hinaus selbstständig Handlungen planen und ausführen kann. Grundsätzlich können derartige Agenten mit den unterschiedlichsten Tools kombiniert werden, etwa zum Suchen von Informationen aus einer Datenbank, zum Abfragen einer WebAPI, zur Analyse von Bildern oder zur Erstellung einer Website. Natürlich kann man diese sehr unterschiedlichen Tools zur Ausführung alle in einem Agenten kombinieren, und einen genrealistischen Agent bauen; jedoch muss man dann Kompromisse machen. Manche Aufgaben erfordern ein besonders gutes und teures Sprachmodell, für andere reicht ein kleines Modell mit Fine-Tuning. Selbst wenn nur ein Modell für alles genutzt wird, empfehlen sich meist unterschiedliche Konfigurationen, etwa ein niedriger Temperature-Wert für Programmieraufgaben, ein höherer für kreatives Schreiben. Darüber hinaus brauchen Agenten, die etwa Informationen aus einer Datenbank extrahieren sollen, ausführliche Informationen zu Tabellenschemata im System-Prompt, sodass unterschiedliche Tools hier stark konkurrieren würden. Zu guter Letzt stellt sich die Frage, warum ein Agent alles gleichzeitig können sollte, wenn sich in der UNIX- und Microservice-Philosophie immer wieder gezeigt hat, dass unterschiedliche Aufgaben in unterschiedlichen Teilen behandelt werden sollten.
Autogen – das erste Framework für Multi-Agent-Systeme
Autogen ist ein Framework zur Erstellung solcher Multi-Agenten-Systeme. Es basiert auf einem 2023 vorgestellten Paper und ist als Open-Source-Repository von Microsoft verfügbar. Im Autogen-Konzept sind Multi-Agenten-Systeme Gruppenkonversationen zwischen verschiedenen conversable_agent Objekte, die durch eine Python-Klasse manifestiert sind. Es gibt 3 Arten von Conversable Agents:
- UserProxyAgent: Repräsentieren den Nutzer. Sie senden die Eingaben des Nutzers in die Konversation und geben das Ergebnis zurück. Darüber hinaus sind sie auch zuständig für das eigentliche Ausführen von Funktionen, die von anderen Agenten aufgerufen werden.
- GroupChatManager: Verwaltet den Gesprächsfluss zwischen den Agenten. Dieser wähl zudem nach der Antwort eines Agenten den nächsten zuständigen Agenten. Dies erfolgt je nach Konfiguration entweder selbst durch den Aufruf eines Language Models oder nach einfachen Heuristiken (zufällig, round-robin).
- AssistantAgent: Die eigentlichen inhaltlichen Agenten, welche spezifisch für die gewünschten Aufgaben konfiguriert werden.
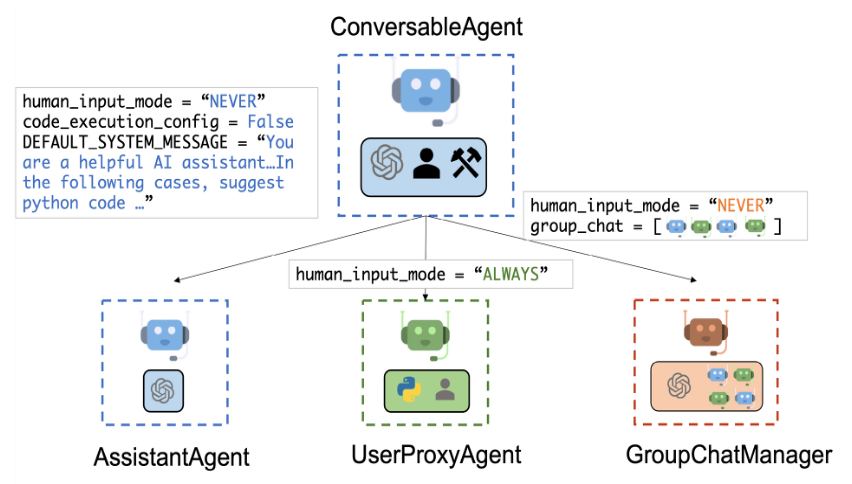
Das Basis-Konzept besteht darin, dass ein Agent einem anderen eine Nachricht sendet, mit der optionalen Bitte um eine Antwort. Kombiniert man nun mehrere solcher Agenten in einen Gruppen-Chat, so werden die Nachrichten nicht nur einem, sondern in der Regel allen Teilnehmern weitergeleitet, sodass eine gemeinsame Chat-Historie entsteht. Auf diese Art haben Agenten einen gemeinsamen Wissenspool und können auf der Arbeit der Vorgänger aufbauen. Hierfür finden sich bei Autogen zahlreiche Beispiele, etwa um mit Hilfe eines Programmierers zunächst relevante Paper herunterzuladen und diese von einem Produktmanager anschließend daraus Produktideen generieren zu lassen. Gleichzeitig führt dieses Vorgehen bei größeren und komplexeren Gruppengesprächen dazu, dass die Chat-Historie schnell wächst und Abfragen langsamer und teurer werden.
llm_config = {"config_list": config_list_gpt4, "cache_seed": 42}
user_proxy = autogen.UserProxyAgent(
name="User_proxy",
system_message="A human admin.",
code_execution_config={
"last_n_messages": 2,
"work_dir": "groupchat",
"use_docker": False,
},
human_input_mode="TERMINATE",
)
coder = autogen.AssistantAgent(
name="Coder",
llm_config=llm_config,
)
pm = autogen.AssistantAgent(
name="Product_manager",
system_message="Creative in software product ideas.",
llm_config=llm_config,
)
groupchat = autogen.GroupChat(agents=[user_proxy, coder, pm], messages=[], max_round=12)
manager = autogen.GroupChatManager(groupchat=groupchat, llm_config=llm_config)
user_proxy.initiate_chat(
manager, message="Find a latest paper about gpt-4 on arxiv and find its potential applications in software.")
Für zahlreiche Applikationen wäre es nützlich, nicht eine offene Gruppendiskussion zwischen allen Agenten zu führen, sondern den Gesprächsverlauf genauer zu kontrollieren. Auch dies ist mit Autogen prinzipiell möglich und es existieren ein paar Beispiele, wie etwa ein Schachspiel, bei dem zwei Spieler einerseits mit dem Spiel, andererseits miteinander kommunizieren. Hierfür müssen speziellere AssistantAgent-Klassen erstellt werden, welche mit Hilfe von register_reply zusätzliche Antworten-Funktionen registrieren. Der erste Parameter ist dabei als ein Filter zu verstehen, für welche Art von Nachrichtensender diese Antwortfunktion genutzt werden soll. In der Antwortfunktion wird im Fall von _generate_board_reply die besondere Logik des Schachspiels abgehandelt und ein Tuple aus True und dem gewählten Zug zurückgegeben. Das True besagt, dass die Funktion eine abschließende Antwort generiert hat und entsprechend keine weiteren registrierten Antwort-Funktionen ausgeführt werden sollen.
sys_msg = """You are an AI-powered chess board agent.
You translate the user's natural language input into legal UCI moves.
You should only reply with a UCI move string extracted from the user's input."""
class BoardAgent(autogen.AssistantAgent):
board: chess.Board
correct_move_messages: Dict[autogen.Agent, List[Dict]]
def __init__(self, board: chess.Board):
super().__init__(
name="BoardAgent",
system_message=sys_msg,
llm_config={"temperature": 0.0, "config_list": config_list_gpt4},
max_consecutive_auto_reply=10,
)
self.register_reply(autogen.ConversableAgent, BoardAgent._generate_board_reply)
self.board = board
self.correct_move_messages = defaultdict(list)
def _generate_board_reply(
self,
messages: Optional[List[Dict]] = None,
sender: Optional[autogen.Agent] = None,
config: Optional[Any] = None,
) -> Union[str, Dict, None]:
message = messages[-1]
# extract a UCI move from player's message
reply = self.generate_reply(
self.correct_move_messages[sender] + [message], sender, exclude=[BoardAgent._generate_board_reply]
)
uci_move = reply if isinstance(reply, str) else str(reply["content"])
try:
self.board.push_uci(uci_move)
except ValueError as e:
# invalid move
return True, f"Error: {e}"
else:
# valid move
m = chess.Move.from_uci(uci_move)
display( # noqa: F821
chess.svg.board(
self.board, arrows=[(m.from_square, m.to_square)], fill={m.from_square: "gray"}, size=200
)
)
self.correct_move_messages[sender].extend([message, self._message_to_dict(uci_move)])
self.correct_move_messages[sender][-1]["role"] = "assistant"
return True, uci_move
Mit Hilfe dieser Logik lassen sich prinzipiell vielfältige Kommunikationsmuster erstellen, in der Praxis wird diese Logik insbesondere bei komplexeren Setups diese Logik aber schnell kompliziert und unübersichtlich, denn der Nachrichtenfluss wird in vielen verschiedenen Klassen zerstreut definiert und hängt von Sender und Position der Antwort-Registration ab. Soll darüber hinaus auch gesteuert werden, wer welche Informationen erhält, so muss dies gesondert innerhalb des GroupChatManagers geregelt werden, was anspruchsvolle Kommunikationsflüsse weiter erschwert.
Fazit
Multi-Agenten-Systeme sind hilfreich, wenn komplexere (teil-)autonome Systeme gebaut werden sollen. Sie ermöglichen es, für jede Teilaufgabe einen speziellen Agenten zu definieren mit Hinblick auf Prompting, Modellauswahl und Konfiguration. Autogen war das erste Framework, das Entwickler bei der Definition solcher Systeme unterstützt und bietet zahlreiche Beispiele, insbesondere für offene Gruppengespräche. Sollen jedoch ein bewusst gesteuerter Informationsfluss realisiert werden, ist Autogen aufgrund seines Designs weniger geeignet. Hierfür empfehlen wir einen Blick in den zweiten Teil dieser Blogpost Reihe: Multi-Agenten-LLM-Systeme kontrollieren mit LangGraph

Nico Kreiling, Data Scientist bei scieneers GmbH
nico.kreiling@scieneers.de



 Photo courtesy of Lwala Community Alliance
Photo courtesy of Lwala Community Alliance


