In der heutigen Geschäftswelt versucht man mehr und mehr, Entscheidungen und Prozesse auf ein solides Fundament von Daten zu stellen. Die technische Antwort darauf sind typischerweise Data Warehouses und Dashboards, die Unternehmensdaten bündeln und durch Visualisierung für jeden verständlich und nutzbar machen.
In der Umsetzung verlässt man sich häufig auf Batch-Processing, bei dem die Daten in einem automatischen Prozess gesammelt und aufbereitet werden – beispielsweise einmal pro Tag, seltener schon stündlich oder im Abstand von einigen Minuten.
Dieser Ansatz funktioniert für viele Anwendungsfälle gut. Er stößt aber dann an seine Grenzen, wenn wir Informationen „in Echtzeit“ analysieren möchten und höchstens eine Verzögerung von wenigen Sekunden in Kauf nehmen können. Einige Beispiele:
Produktion: Überwachung von Sensordaten, um Maschinenausfälle zu vermeiden („Predictive Maintenance“)
Supply Chain: Tracking von Standortdaten und Wetterereignissen, um Lieferverzögerungen frühzeitig zu erkennen
Finanzwesen: Sekundengenaue Überwachung und Analyse von Aktienkursen
IT: Auswertung von Log-Daten, um nach Updates Probleme sofort zu erkennen
Marketing: Analyse von Social Media Posts während einem Live-Event
Neu ist das alles nicht, aber bisherige Lösungen waren in der Umsetzung oft aufwendig und erforderten viel Fachwissen.
Genau hier hat Microsoft angesetzt: 2024 wurde die Fabric-Plattform mit Real-Time Intelligence um verschiedene Bausteine erweitert, mit denen man einen Großteil der Komplexität umgeht und schnell zu funktionierenden Lösungen kommt.
In kommenden Artikeln erklären wir die wichtigsten dieser Bausteine „Fabric Items“ genauer. Hier ein kurzer Überblick:
Eventstream
Eventstreams empfangen kontinuierlich Echtzeitdaten (Events) aus verschiedensten Quellen. Diese werden bei Bedarf transformiert und letztlich an ein Ziel weitergeleitet, das für die Speicherung der Daten zuständig ist. Typischerweise ist das Ziel ein Eventhouse. Code wird nicht benötigt.
Eventhouse
Ein Eventhouse ist ein optimierter Datenspeicher für Events. Es enthält mindestens eine KQL-Datenbank, in der die Event-Daten in Tabellenform gespeichert werden.
Real-Time Dashboard
Real-Time Dashboards haben Ähnlichkeit zu Power-BI-Reports, sind aber eine von Power BI unabhängige, eigenständige Lösung. Ein Real-Time Dashboard enthält Kacheln mit Visuals (z.B. Diagramme oder Tabellen). Diese sind interaktiv und man kann etwa Filter setzen. Jedes Visual holt sich die notwendigen Daten über eine Datenbankabfrage, die man in KQL (Kusto Query Language) formuliert – typischerweise aus einem Eventhouse.
Activator
Activator ermöglicht es, unter bestimmten Bedingungen automatisch eine Aktion auszuführen, beispielsweise basierend auf einem Real-Time Dashboard oder einer KQL Query. Die Aktion ist im einfachsten Fall das Senden einer Nachricht per E-Mail oder Teams; man kann aber auch einen Power Automate Flow anstoßen.
Was muss ich also lernen, um mit Real-Time Intelligence eine Lösung umzusetzen?
Es läuft im Wesentlichen auf KQL und ein Grundverständnis der erwähnten Fabric Items hinaus. Vieles ist No-Code. KQL ist zwar im Vergleich zu SQL weniger verbreitet, die Grundlagen sind aber leicht zu lernen und es fühlt sich schon nach kurzer Zeit natürlich an.
In unserem Blogmelden wir uns bald mit weiteren Posts zum Thema Fabric Real-Time Intelligence und steigen tiefer in die verschiedenen Themenbereiche ein.
https://www.scieneers.de/wp-content/uploads/2025/05/real_time_intelligence_1030x258.jpg258344Rupert Schneiderhttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngRupert Schneider2025-05-23 09:37:392025-05-23 14:46:06Real-Time Intelligence: Echtzeitdaten in Microsoft Fabric
Microsoft Fabric ist eine vielseitige und leistungsstarke Plattform für aktuelle Daten- und Analyseanforderungen und genießt derzeit große Aufmerksamkeit bei unseren Kunden. Dabei begegnen wir ganz unterschiedlichen Bedürfnissen – abhängig von Unternehmensgröße, Datenkultur und dem jeweiligen Entwicklungs- und Analysefokus.
Kunden aus dem Power-BI-Umfeld profitieren insbesondere von der Erweiterung des Self-Service-Ansatzes: Über vertraute Weboberflächen und ohne spezialisierte Entwicklungsprogramme können selbst Fachabteilungen oder Enduser schnell in die Datenaufbereitung einsteigen.
Erfahrene Entwickler:innen und IT-Teams möchten hingegen sicherstellen, dass sie in Fabric nicht auf bewährte Abläufe, wie die Entwicklung in einer IDE, Versionsverwaltung via Git oder etablierte Test- und Rollout-Prozesse, verzichten müssen. Dabei stellt sich die Frage, wie zentrale Änderungen robust geprüft und einer Vielzahl von Usern zur Verfügung gestellt werden können.
In diesem Blogpost möchten wir einen Überblick über die Entwicklungs- und Kollaborationsmöglichkeiten sowie die verschiedenen Deployment-Szenarien in Fabric geben. Obwohl wir versuchen, einen allgemeinen Überblick darzustellen, arbeitet Microsoft aktuell mit Hochdruck an neuen Funktionen und Verbesserungen für Fabric, sodass sich technische Einzelheiten mit der Zeit ändern können. Der jeweils aktuelle Stand zur Entwicklung von Fabric ist in der offiziellen Dokumentation oder im Microsoft-Fabric-Blog zu finden.
Fabric als Software-as-a-Service wird in der Regel direkt über den Browser bedient.
Wer bereits den Power BI Service kennt, findet sich dank des vertrauten Workspace-Konzepts sofort zurecht. Neue Fabric-Objekte wie Dataflows oder Data Pipelines lassen sich unkompliziert in der Weboberfläche erstellen und bearbeiten – eine lokale Entwicklungsumgebung oder zusätzliche Softwareinstallationen sind dafür nicht nötig.
Ein weiterer wesentlicher Vorteil der browserbasierten Entwicklung in Fabric ist die plattformunabhängige Nutzbarkeit unter Windows und macOS. Allerdings sind Entwicklungsumgebung im Browser allgemein weniger flexibel und anpassbar als eine vollständige Entwicklungsumgebung (IDE), da nur ein eingeschränkter Umfang an Tools und Integrationsmöglichkeiten zur Verfügung steht. Das ist auch in Bezug auf Fabric der Fall.
Änderungen an Fabric-Objekten sind sofort live und können direkt von anderen Usern gesehen und getestet werden, wodurch sich die Entwicklungszyklen deutlich beschleunigen. Allerdings bringt diese unmittelbare Sichtbarkeit auch Risiken mit sich: Fehler oder ungewollte Änderungen wirken sich sofort auf alle User aus und lassen sich nicht so einfach rückgängig machen wie in lokal gespeicherten Dateien.
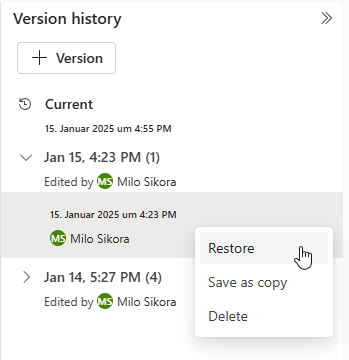
Aus diesem Grund arbeitet Microsoft an einer integrierten Versionierung, inklusive Rollback-Funktionalität für verschiedene Fabric-Objekte. Für Notebooks ist diese Funktion bereits verfügbar, für semantische Modelle befindet sie sich aktuell in der Preview-Phase.
Trotz einiger Einschränkungen bei Flexibilität und Tool-Integration bietet die Weboberfläche damit einen schnellen, bequemen Einstieg in die Entwicklung und vereinfacht die Zusammenarbeit in verteilten Teams. Beispielsweise unterstützt die Notebook-GUI paralleles Arbeiten, einschließlich Kommentaren und Cursor-Highlighting, was Pair Programming, Remotedebugging oder auch Tutoren-Szenarien erleichtert.
Dieser Entwicklungsprozess ist vor allem für Szenarien geeignet, in denen eine isolierte Entwicklung nicht erforderlich ist und Änderungen direkt am Live-Stand vorgenommen werden können – beispielsweise für Enduser in nicht-technischen Fachabteilungen oder weniger kritische Anwendungsfälle.
Benötigt man hingegen eine dedizierte Umgebung, um neue Funktionen oder Anpassungen zu testen, ohne den Live-Stand zu beeinflussen, stehen grundsätzlich zwei Ansätze zur Verfügung.
2. Isolierte Entwicklung mittels lokaler Client-Tools
Für verschiedene Fabric-Objekte stehen Client-Tools zur Verfügung, die auf einem Rechner installiert werden können und mit denen sich diese Objekte lokal bearbeiten lassen. Meist wird dazu eine lokale Kopie des Fabric-Objekts erzeugt, diese wird bearbeitet und nach Fertigstellung aller Änderungen wieder in den Fabric Workspace hochgeladen.
Power-BI-User kennen diesen Ablauf bereits: Ein Power-BI-Report aus Fabric kann als .pbix-Datei heruntergeladen und mit Power BI Desktop lokal bearbeitet werden. Die Änderungen am Report werden in Fabric erst sichtbar, wenn man die lokalen Änderungen veröffentlicht. Vergleichbar läuft das Bearbeiten von Fabric-Notebooks ab, welche als .ipynb-Datei exportiert und lokal mit den präferierten Entwicklungstools bearbeitet werden können. Für VS Code gibt es eine Erweiterung (derzeit noch unter dem Namen „Synapse“) die diesen Prozess vereinfacht.
Hat man diese VS-Code-Erweiterung installiert, kann man direkt über einen Button in der Fabric-GUI eine lokale Kopie des gewünschten Notebooks erzeugen und in VS Code öffnen.
So arbeitet man in einer gewohnten Entwicklungsumgebung. Bei Bedarf kann man den Code über die fabric-spark-runtime sogar auf der Fabric-Kapazität ausführen lassen und damit große Datenmengen verarbeiten. Sobald alle Änderungen am Notebook erfolgt sind, lädt man die angepasste Version einfach wieder über das VS-Code-Plugin in den Fabric Workspace hoch – inklusive praktischer Diff-Funktion, um Unterschiede gegenüber der Version im Fabric Workspace anzuzeigen.
Darüber hinaus kann auch in anderen Bereichen mit lokalen Tools auf die Fabric-Umgebung zugegriffen werden. Beispielsweise lassen sich VS Code oder SQL Server Management Studio verwenden, um SQL-Abfragen zu schreiben oder Views zu definieren. Besonders das Fabric Warehouse ist aktuell gut in diese Tools integriert, eine Verbindung ist grundsätzlich aber mit allen SQL-basierten Fabric-Objekten möglich.
Die vorgestellten Funktionen sind ohne eine Anbindung des Fabric-Workspaces an ein Git-Repository nutzbar. Damit eignet sich dieser Prozess besonders für User, die eine isolierte Entwicklungsumgebung benötigen, jedoch noch keine Erfahrung mit Git haben oder deren Workspaces aus organisatorischen Gründen (noch) nicht an ein Git-Repository angebunden sind.
Für erfahrene Entwickler:innen ist eine Git-Integration jedoch ein zentraler Baustein professioneller Entwicklungsprozesse. Aus diesem Grund bietet Microsoft Fabric auch eine native Integration in Azure DevOps und GitHub.
Einschub: Fabric Git-Integration
Microsoft Fabric ermöglicht es, einen Workspace mit einem Azure DevOps- oder GitHub-Repository zu verbinden, um die Vorteile eines Git -integrierten Entwicklungsprozesses, wie beispielsweise die Versionierung, zu nutzen. Eine ausführliche Erläuterung aller Funktionen und Einschränkungen dieser Funktionalität findet sich hier.
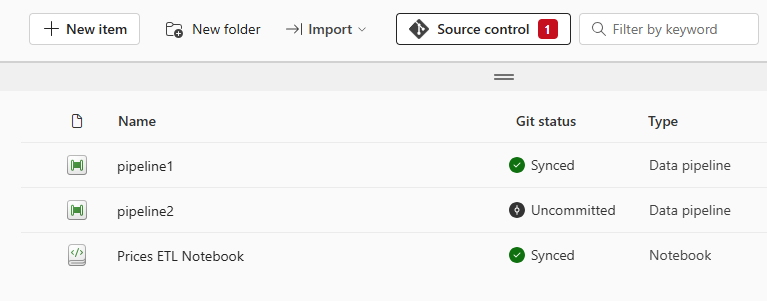
Ist ein Workspace an ein Repository angebunden, kann jederzeit der Git-Status der einzelnen Fabric-Objekte eingesehen werden. Änderungen an Objekten oder das Erstellen neuer Objekte können direkt aus der GUI heraus committet und in dem Repository gespeichert werden. Dadurch ist sicher gestellt, dass versehentlich gelöschte Objekte jederzeit wiederhergestellt werden können.
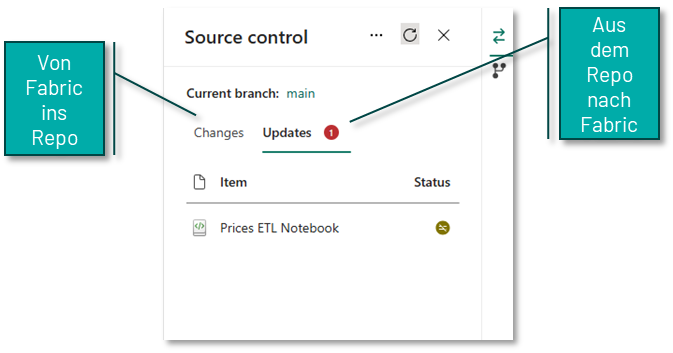
Es ist wichtig zu verstehen, dass diese Synchronisation zwischen Fabric und dem Repository in beide Richtungen erfolgen kann. Es können also Änderungen aus Fabric in das Repository gesichert werden und ebenso Änderungen an den Objekten im Repository (z.B. wenn ein Notebook direkt im Repository bearbeitet wurde) zurück in den Fabric Workspace importiert werden.
Wenn der Fabric Workspace Git-integriert ist, eröffnet das weitere Möglichkeiten, lokal mit verschiedenen Fabric-Elementen zu arbeiten. Durch das Klonen des entsprechenden Repositories kann man alle bekannten Git-Features nutzen, wie zum Beispiel lokale Feature-Branches oder einzelne Commits für wichtige Zwischenstände.
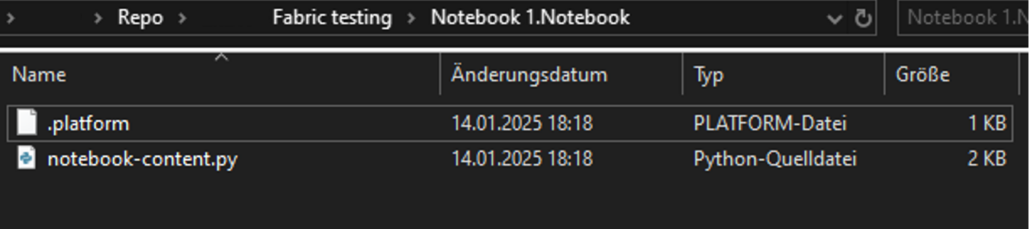
Ein Nachteil dabei ist jedoch, dass einzelne Fabric-Objekte im Repository in Formaten gespeichert werden, die primär auf eine Git-optimierte Speicherung und nicht auf eine komfortable Bearbeitung ausgelegt sind. Notebooks werden beispielsweise nicht als .ipynb-Dateien gespeichert, sondern als reine .py-Dateien, ergänzt durch eine zusätzliche .platform-Datei, die wichtige Metadaten enthält. Das kann das lokale Arbeiten mit Branches im Repository erschweren.
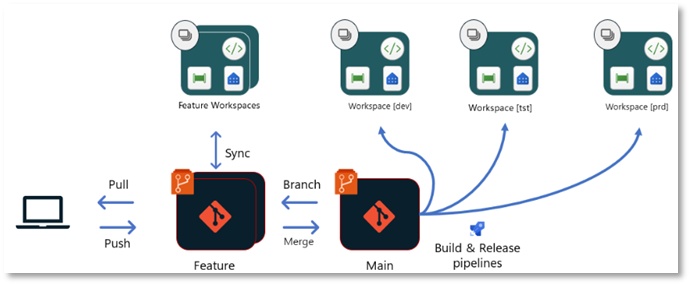
3. Isolierte Entwicklung in Feature-Branch Workspaces
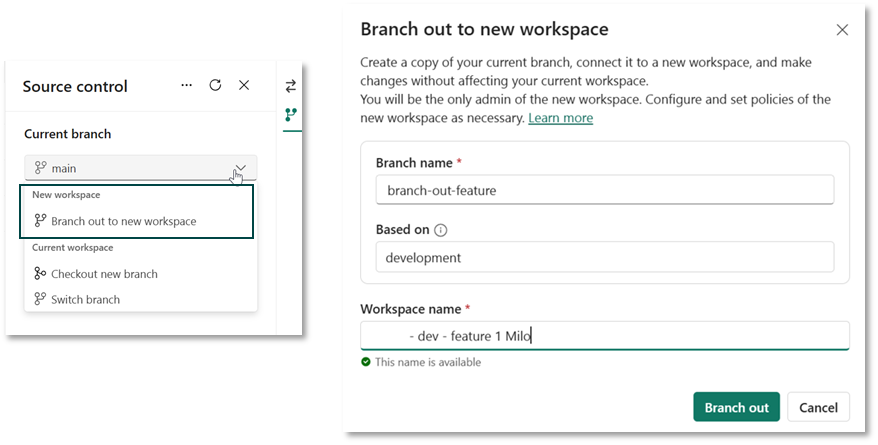
Um eine isolierte Entwicklungsumgebung zu erreichen, muss man in Fabric nicht zwangsläufig auf lokale Tools ausweichen. Fabric bietet – vorausgesetzt, der Workspace ist Git-integriert – auch native Möglichkeiten. Besonders interessant ist hierbei die Funktion “Branch out to a new feature-workspace”, die hier näher beschrieben wird.
Nutzt man dieses Feature, wird eine Kopie des Workspaces erstellt, auf den zunächst nur man selber Zugriff hat. In diesem kann man isoliert entwickeln, ohne die Funktionalität der Objekte im eigentlichen Workspace zu beeinflussen. Im Hintergrund passiert Folgendes:
Es wird ein neuer, leerer Workspace mit dem definierten Namen angelegt.
In diesen Branch wird der Inhalt des aktuellen Workspaces kopiert.
Im Repository wird ein neuer Branch angelegt, dessen Namen ebenfalls bestimmt werden kann.
Im neu angelegten Workspace werden die Fabric-Objekte basierend auf dem neu angelegten Branch erstellt.
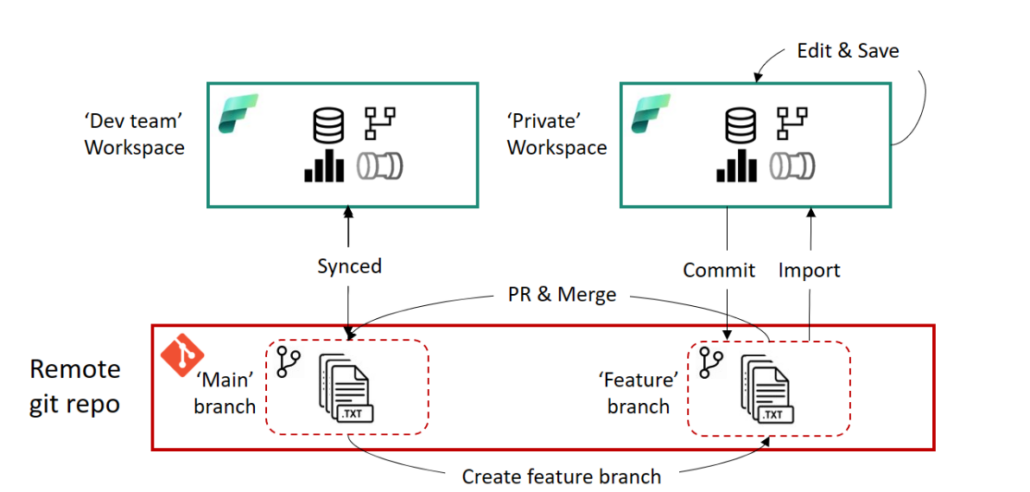
Man kann nun isoliert an den Fabric-Objekten arbeiten und die Änderungen in den neuen Branch committen, beispielsweise wenn man an einem Notebook weiterentwickeln möchte. Wichtig hierbei ist, dass Daten (z.B. in einem Lakehouse) nicht im Repository gespeichert werden und somit auch nicht in dem neuen Workspace zur Verfügung stehen. Das bedeutet, ein Notebook verbindet sich weiterhin mit dem Lakehouse in dem eigentlichen Workspace, wenn dieses im Notebook als Datenquelle genutzt wurde.
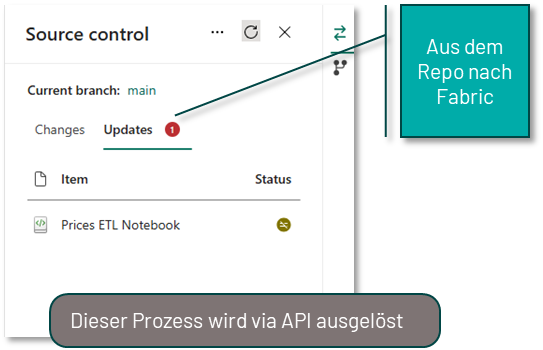
Hat man alle Änderungen in dem Feature-Workspace durchgeführt, muss man diese Änderungen noch zurück in den eigentlichen Workspace übertragen. Dieser Prozess erfolgt primär in Azure DevOps bzw. GitHub und setzt ein grundlegendes Verständnis von Git voraus. Man erstellt hierfür einen Pull-Request (PR), um den Feature-Branch in den Main-Branch des eigentlichen Workspaces zu mergen. Hierbei stehen alle gewohnten Funktionalitäten von DevOps und GitHub zur Verfügung, wie z.B. das Taggen von Reviewern. Ist der PR erfolgreich abgeschlossen, hat der Main-Branch im Repository einen aktuelleren Stand als die Fabric-Objekte im Workspace selbst. Abschließend muss der Stand aus dem Repository also noch in den Workspace übertragen werden. Hierfür kann man den oben beschriebenen Prozess des Updates im Source Control Panel des Fabric Workspaces nutzen oder diesen Prozess via API automatisieren.
Das folgende Diagramm veranschaulicht diesen Prozess.
Dieser Entwicklungsprozess bietet die umfassenden Vorteile einer Git-basierten Entwicklung und lässt sich bei Bedarf zusätzlich mit lokalen Client-Tools ergänzen. So ist es beispielsweise möglich, die Notebooks im Feature-Workspace über den oben beschriebenen Prozess in VS Code zu öffnen.
Dennoch bringt dieser Prozess auch einige Nachteile mit sich. Da Pull-Requests und Merges in Azure DevOps bzw. GitHub durchgeführt werden, setzt dieser Prozess Erfahrung im Umgang mit Git sowie Azure DevOps oder GitHub voraus. Außerdem müssen User, die dieses Feature in Fabric nutzen möchten, die Berechtigung haben, Workspaces zu erstellen, was zunächst von einem Administrator freigegeben werden muss. Zum aktuellen Zeitpunkt werden die Feature-Workspaces zudem nicht automatisch gelöscht, nachdem ein erfolgreicher Merge in den Ausgangs-Workspace durchgeführt wurde. Dies kann dazu führen, dass sich im Laufe der Zeit einige nicht mehr benötigte Workspaces ansammeln, wenn diese nicht manuell gelöscht werden.
Deployment Prozesse
Ein weiterer Schritt zur Professionalisierung des Einsatzes von Microsoft Fabric besteht darin, Workloads in mehreren Umgebungen bzw. Environments zu betreiben. In der Regel wird zwischen einer Entwicklungsumgebung (Dev.) und einer Produktivumgebung (Prod.) unterschieden. Dies ermöglicht es, den Workload in der Entwicklungsumgebung isoliert und iterativ weiterzuentwickeln, während die Enduser in der Produktivumgebung jederzeit eine funktionierende und gut dokumentierte Version des Workloads vorfinden.
Sobald ein zufriedenstellender Punkt im Entwicklungsprozess erreicht ist, wird der Entwicklungsstand von der Entwicklungsumgebung in die Produktivumgebung übertragen. Dieser Vorgang wird als Deployment-Prozess bezeichnet. Microsoft Fabric bietet hierfür verschiedene Möglichkeiten.
1. Fabric Deployment Pipelines
Die einfachste Möglichkeit, einen Deployment-Prozess in Fabric zu integrieren, sind die sogenannten Fabric Deployment Pipelines. Sie sind fester Bestandteil von Fabric und benötigen kein weiteres Tooling – um sie zu benutzen, muss der Entwicklungs-Workspace nicht einmal mit einem Git-Repository verknüpft sein.
Für jede Umgebung wird ein Workspace angelegt, und anschließend wird in dem Entwicklungs-Workspace eine Deployment Pipeline aufgesetzt. Über ein übersichtliches Interface definiert man, welche Fabric-Objekte vom Ausgangs-Workspace (in der Darstellung unten „Development“) in den Ziel-Workspace (in unserem Fall „Test“) übertragen werden sollen, und klickt auf „Deploy“.
Da sich unterschiedliche Umgebungen in der Regel in ihren Eigenschaften unterscheiden – beispielsweise in der Datenbank, auf die sie zugreifen – lassen sich für jedes Fabric-Objekt sogenannte Deployment-Rules definieren. Diese stellen sicher, dass diese Eigenschaften während des Deployment-Prozesses entsprechend angepasst werden.
Zum aktuellen Zeitpunkt sind diese Deployment-Rules jedoch noch nicht für alle Fabric-Objekte einsetzbar und unterstützen nur eine vordefinierte Auswahl an Eigenschaften, die angepasst werden können. So kann man beispielsweise in einem Fabric-Notebook keine zuvor im Code definierten Parameterwerte austauschen.
Insgesamt bieten die Fabric Deployment Pipelines einen einfachen Einstieg in die Entwicklung mit mehreren Umgebungen, ohne dass tiefgreifende Erfahrung mit Git notwendig ist. Sie eignen sich besonders für Workloads, die beispielsweise von nicht-technischen Fachabteilungen verwaltet werden, und stellen eine logische Erweiterung des Self-Service-Prinzips dar.
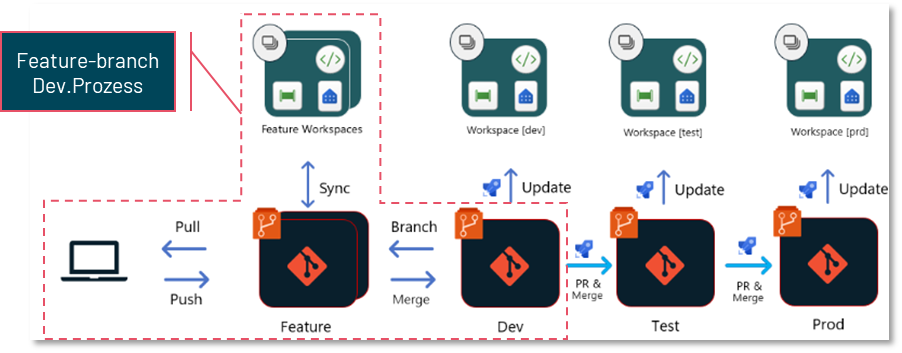
2. Branch-based Deployment
Die zweite Möglichkeit, einen Deployment-Prozess in Fabric umzusetzen, erfordert, dass alle Workspaces, die eine bestimmte Umgebung darstellen (z.B. Dev., Test. und Prod.), mit verschiedenen Branches desselben Git-Repositories verknüpft sind. Die Funktionsweise des branch-basierten Deployments ähnelt dem Feature-Branch-Entwicklungsprozess, der im folgenden Diagramm gekennzeichnet ist. Grundsätzlich ist der branch-basierte Deployment-Prozess jedoch mit allen Entwicklungsprozessen kombinierbar, solange eine Git-Integration eingerichtet ist.
Dieser Prozess nutzt die Funktionalität von Azure DevOps Pipelines (bzw. GitHub Actions), die automatisch auf Änderungen in Repository-Branches reagieren und bestimmte Prozesse anstoßen können.
Sobald ein neuer Entwicklungsstand in der Entwicklungsumgebung (Dev.) entwickelt wurde und bereit für das Deployment ist, wird im Repository ein Pull-Request (PR) in einen Test-Branch eröffnet. In diesem Branch können Reviewer die neuen Änderungen überprüfen und freigeben.
Nach der Freigabe und Aktualisierung des Test-Branches wird automatisch eine DevOps-Pipeline gestartet, die verschiedene Aktionen auf den Objekt-Definitionen in diesem Branch ausführt. Diese Pipeline kann beispielsweise Umgebungsparameter (wie Datenbankverbindungen) anpassen, automatisierte Tests auf dem Code durchführen oder sicherstellen, dass der Code den Stil- und Benennungskonventionen entspricht.
Der angepasste Code wird dann in einem weiteren Branch, wie z.B. Test-Release, gespeichert. Dieser Test-Release-Branch ist mit dem Test-Workspace in Fabric verbunden. Eine zweite Pipeline reagiert auf die Aktualisierung dieses Branches und sorgt über eine API dafür, dass der Stand aus diesem Branch in den Fabric-Workspace übertragen wird.
Im Test-Workspace können anschließend direkt in Fabric weitere Tests, wie Data-Quality-Tests, durchgeführt werden, bevor der Code über einen analogen Prozess in den produktiven Workspace übertragen wird.
Diese Form des Deployment-Prozesses erfordert neben dem Verständnis von Git auch Erfahrung im Aufsetzen von Azure DevOps Pipelines bzw. GitHub Actions und ist daher für erfahrene Entwickler:innen und kritische Workloads konzipiert. Die Verwendung professioneller Deployment-Tools bietet dann jedoch die volle Flexibilität in der Ausgestaltung des Deployment-Prozesses und der Integration erweiterter Schritte wie Code-Testing.
Die Arbeit mit dedizierten Branches pro Umgebung erlaubt außerdem das einfache Handling verschiedener Versionen in den einzelnen Umgebungen sowie das schnelle Zurückrollen auf vorherige Stände.
3. Release-Pipeline Deployment
Eine weitere Möglichkeit für ein Deployment in Fabric besteht darin, die einzelnen Workspaces nicht direkt über die integrierten Möglichkeiten mit einem Branch in einem Repository zu verbinden, sondern ausgehend von einem geteilten Main-Branch über Build- und Release-pipelines direkt in die einzelnen Workspaces zu deployen.
Bei diesem Ansatz kann – wie im vorherigen Prozess auch – eine Build-Pipeline je nach Zielumgebung Umgebungsparameter (wie Datenbankverbindungen) austauschen, automatisierte Tests auf dem Code durchführen oder sicherstellen, dass der Code den Stil- und Benennungskonventionen entspricht. Das Ergebnis wird in diesem Ansatz jedoch nicht in einem eigenen Branch gespeichert, sondern beispielsweise als Artefakt an eine Release-Pipeline übergeben. Diese nutzt dann die Fabric Item API, um die jeweiligen Fabric-Objekte oder Änderungen in den Ziel-Workspace zu deployen.
Um die Interaktion mit der Fabric API zu vereinfachen, können Libraries wie die fabric-cicd Python Library verwendet werden.
Genau wie das Branch-based Deployment erfordert dieser Ansatz Erfahrung im Umgang mit Azure DevOps Pipelines, erlaubt deshalb aber auch die volle Flexibilität in der genauen Ausgestaltung des Deploymentprozesses.
Fazit
In diesem Artikel haben wir die gängigsten Entwicklungs- und Deploymentprozesse in Microsoft Fabric exemplarisch vorgestellt. Gerade innerhalb der Deploymentprozesse über Azure DevOps bzw. Github besteht in der konkreten Ausgestaltung aber natürlich die volle Flexibiltät, diese genau auf die eigenen Bedürfnisse anzupassen. Es ist außerdem nicht notwendig sich bei allen Workloads, die auf Fabric abgebildet werden sollen, für einen einzigen Entwicklungs- oder Deploymentprozess zu entscheiden. Die Wahl des passenden Prozesses sollte stets auf die spezifischen Anforderungen und den jeweiligen Workload abgestimmt sein. So ist es sinnvoll einen professionellen Deploymentprozess für zentrale Datenprodukte wie z.B. ein unternehmensweites Datawarehouse zu wählen, während für einzelne Fachbereiche evtl. ein Deployment über Deployment Pipelines ausreicht, oder sogar komplett auf Deploymentprozesse verzichtet werden kann.
Wer noch mehr Tipps und Tricks zu Microsoft Fabric erfahren möchte, sollte einen Blick in unseren Microsoft Fabric Kompakteinführung Workshop werfen!
Zusammen mit der Carl Remigius Fresenius Education Group (CRFE) entwickelten wir NextGeneration:AI. Dabei handelt es sich um eine datenschutzkonforme Plattform zur Nutzung von Sprachmodellen für alle Studierende und Mitarbeitende der CRFE. Das besondere an NextGeneration:AI ist die Authentifizierung über das Learning Management System Ilias mit Hilfe einer LTI-Schnittstelle, sowie die umfassende Personalisierbarkeit, die Nutzer:innen geboten wird. Im Blogartikel gehen wir auf die Details der Implementierung ein.
350 Millionen, fast 5% der Weltbevölkerung leben mit einer seltenen Erkrankung. Etwa 75% der seltenen Erkrankungen betreffen Kinder. 80% dieser Erkrankungen entstehen durch eine einzige genetische Veränderung und können durch eine Genomanalyse diagnostiziert werden. Das menschliche Genom besteht aus etwa 3.3 Milliarden Bausteinen und jeder Mensch trägt etwa 3.5 Millionen Varianten. Die Suche nach der einen, pathogenen Variante, als Ursache der Krankheit, gleicht der Suche nach der Nadel im Heuhaufen.
https://www.scieneers.de/wp-content/uploads/2024/02/dna-3539309_1920.jpg9601920Martin Dannerhttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngMartin Danner2024-02-29 16:55:032024-03-01 12:56:49Erforschung des Dark Genome mit Machine Learning zur Entwicklung neuartiger Krankheitsinterventionen
Zusammen mit der RWTH Aachen University haben wir rwthGPT entwickelt: Eine datenschutzkonforme Plattform zur Nutzung von OpenAI-Modellen für Studierende und Mitarbeitende. Ergänzt wird rwthGPT durch ein dediziertes User-Management mit Kostenzuordnung, das Speichern von Chat-Verläufen und Talk to your Data. Wir werfen einen detaillierten Blick auf die Datenschutz-relevanten Aspekte.
Am Fallbeispiel der Wärmeprognose bei STEAG New Energies wird die Entwicklung und das Projektvorgehen nach SCRUM und CRISP-DM skizziert. Neben der detaillierten Beschreibung der einzelnen Schritte einer Entwicklungsiteration, liegt ein weiterer Fokus des Blog-Artikels auf dem im Einsatz befindlichen Technologie-Stack.
https://www.scieneers.de/wp-content/uploads/2022/11/data_science_crisp_prozess.jpg12621920Martin Dannerhttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngMartin Danner2022-12-14 15:00:232025-01-31 11:54:47Entwicklung nach SCRUM und CRISP-DM am Fallbeispiel Wärmeprognose bei STEAG New Energies
Mit unserem Training “Data Science für den Arbeitsalltag” möchten wir Unternehmen dabei unterstützen, Wissenslücken in der praktischen Umsetzung von Machine Learning Projekten zu schließen und ein gemeinsames Teamverständnis zu schaffen.
Neben beliebig kombinierbaren Einzel-Modulen bieten wir dafür eine Beratung für Ihre individuelle Data Challenge an.
https://www.scieneers.de/wp-content/uploads/2022/10/puzzle.png10241024Nico Kreilinghttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngNico Kreiling2022-11-15 13:35:392025-06-18 17:21:04Data Science Training für echte Projekte
Datenoptimierte Wärmeprognosen und Fahrplanerzeugung bei KWK-Anlagen – unser spannendes Azure-Daten-Projekt mit Steag New Energies wird hier vorgestellt
https://www.scieneers.de/wp-content/uploads/2022/03/wordpress-2022.png7201281Nico Kreilinghttps://www.scieneers.de/wp-content/uploads/2020/04/scieneers-gradient.pngNico Kreiling2022-04-08 15:45:362025-01-31 11:31:11Studierende zur Erstellung einer Masterarbeit (m/w/d)


















 Steag New Energies GmbH
Steag New Energies GmbH